欢迎来到noYes游戏王国
网站导航
在上一篇文章中,小编为您详细介绍了关于《开源激荡30年:从免费社区到价值数十亿美元公司》相关知识。本篇中小编将再为您讲解标题理解AI最伟大的成就之一:卷积神经网络的局限性。
原标题:理解 AI 最伟大的成就之一:卷积神经网络的局限性

作者 | Ben Dickson
译者 | 香槟超新星
头图 | CSDN 下载自视觉中国
出品 | CSDN(ID:CSDNnews)
经过一段漫长时期的沉寂之后,人工智能正在进入一个蓬勃发展的新时期,这主要得益于深度学习和人工神经网络 近年来取得的长足发展。更准确地说,人们对深度学习产生的新的兴趣在很大程度上要归功于卷积神经网络(CNNs) 的成功,卷积神经网络是一种特别擅长处理视觉数据的神经网络结构。
但是,如果有人告诉你卷积神经网络存在根本性的缺陷,你会怎么看呢?而这一点是被誉为“深度学习鼻祖”和“神经网络之父”的Geoffrey Hinton教授在2020年度人工智能顶级会议 – AAAI大会上作的主题演讲中提出的,AAAI(译注:AAAI全称为美国人工智能协会)大会是每年主要的人工智能会议之一。
Hinton,与Yann LeCun和Yoshua Bengio一起出席了这次会议,这三大深度学习巨头,图灵奖的获得者,被业界并称为“深度学习教父”。Hinton谈到了卷积神经网络(CNNs)和胶囊网络的局限性,并提出这是他在人工智能领域的下一个突破方向。
和他所有的演讲一样,Hinton深入探讨了许多技术细节,这些细节使得卷积神经网络与人类视觉系统相比越来显得效率低下而且不同。本文将会详细阐述他在大会上提出的一些要点。但在我们接触这些要点之前,让我们像以往一样,了解关于人工智能的一些基础知识,以及为什么卷积神经网络(CNNs)对人工智能社区来说如此重要的背景和原因。
计算机视觉的解决方案
在人工智能的早期,科学家们试图创造出一种计算机,它能像人类一样“看”世界。这些努力导致了一个全新的研究领域的产生,这就是计算机视觉 。
计算机视觉的早期研究涉及到符号人工智能 的使用,其中的每个规则都必须由人类程序员指定。但是问题在于,并不是人类视觉设备的每一个功能都可以用明确的计算机程序规则来分解。所以,这种方法的使用率和成功率都非常有限。
另一种不同的方法是机器学习 。与符号人工智能相反,机器学习算法被赋予了一个通用的结构,并通过对训练实例的检验来开发自己的行为能力。然而,大多数早期的机器学习算法仍然需要大量的人工工,来设计用来检测图像相关特征的部件。
卷积神经网络(CNNs),与以上两种方法不同,这是一种端到端的人工智能模型,它开发了自己的特征检测机制。一个训练有素的多层次 卷积神经网络会以一种分层的方式自动识别特征,从简单的边角到复杂的物体,如人脸、椅子、汽车、狗等等。
卷积神经网络(CNNs)最早是在20世纪80年代由LeCun引入,当时他在多伦多大学的Hinton实验室做博士后研究助理。但是,由于卷积神经网络对计算和数据的巨大需求,它们被搁置了下来,它在那个时间获得的采用非常有限。而后,经过三十年的发展,并且借助计算硬件和数据存储技术取得的巨大进步,卷积神经网络开始充分发挥其强大的潜力。
今天,得益于大型的计算集群、专用的硬件和海量的数据,卷积神经网络在图像分类和对象识别方面已经得到了广泛而且有益的应用。

卷积神经网络的每一层都将从输入图像中提取特定的特征。
卷积神经网络(CNNs)与人类视觉的区别
在AAAI大会的演讲中,Hinton指出:“卷积神经网络(CNNs)充分利用了端对端的学习方式。事实证明,如果一项功能在某个地方不错,那么在其他地方也会很不错,因此他们赢得了巨大的成功。这使得它们可以结合证据,并很好地在不同位置进行泛化。然而,它们与人类的感知非常不同。”
计算机视觉的关键挑战之一是处理现实世界中的数据差异。我们的视觉系统可以从不同的角度、不同的背景和不同的光照条件下识别物体。当物体被其他物体部分遮住或以古怪的方式着色时,我们的视觉系统利用线索和其他知识来填补缺失的信息以及我们这样看的理由。
事实证明,创建能够复制相同对象识别功能的人工智能非常困难。
Hinton说:“卷积神经网络(CNNs)是为解决物体的平移问题而设计的”。这意味着一个训练有素的卷积神经网络可以识别一个对象,而不管其在图像中的位置如何。但是他们并不能很好地处理视点变化的其他效果,例如旋转和缩放。
根据Hinton的说法,解决这个问题的一种方法是使用4D或6D地图来训练人工智能,然后执行对象检测。他补充道:“但这实在是令人望而却步。”。
目前,我们最好的解决方案是收集大量的图像,在不同的位置显示每个对象。然后,我们在这个庞大的数据集上训练卷积神经网络,希望它能看到足够多的对象示例以进行泛化,并且能够在真实世界中以可靠的准确度来检测对象。诸如ImageNet这样的数据集包含超过1,400万个带有注释的图像,目的就是旨在实现这一目标。
Hinton说道:“这不是很有效。我们希望卷积神经网络能够毫不费力地推广到新的视点。如果他们学会了识别某些东西,而你把它放大10倍并旋转60度,那么这根本不会给他们带来任何问题。我们知道计算机图形学就是这样,我们希望卷积神经网络更像这样。”
事实上,ImageNet已经被证明是有缺陷的,它目前是评估计算机视觉系统的首选基准。尽管数据集庞大,但是它无法捕获对象的所有可能角度和位置。它主要由在理想照明条件下以已知角度拍摄的图像组成。
这对于人类视觉系统来说是可以接受的,因为它可以轻松地进行知识泛化。事实上,当我们从多个角度观察到某个对象后,我们通常可以想象它在新位置和不同视觉条件下的外观。
但是卷积神经网络(CNNs)需要详细的示例来说明他们需要处理的案例,而且他们不具备人类思维的创造力。深度学习开发人员通常试图通过应用一个称为“数据增强”的过程来解决这个问题,在这个过程中,他们在训练神经网络之前翻转图像或少量旋转图像。实际上,卷积神经网络将在每个图像的多个副本上进行训练,每个副本都会略有不同。这将有助于人工智能针对同一对象的变化进行泛化。在某种程度上,数据增强使得人工智能模型更加健壮。
然而,数据增强无法涵盖卷积神经网络和其他神经网络无法处理的极端情况,比如说,一张上翘的椅子,或者放在床上的一件皱巴巴的T恤衫。这些都是现实生活中像素操纵无法实现的情况。

ImageNet与现实对比:在ImageNet(左列)中,对象放置整齐,处于理想的背景和光照条件下。而现实世界比它混乱得多(资料来源:objectnet.dev)
已经有人通过创建能够更好地表示现实世界的混乱现实的计算机视觉基准和训练数据集来解决这一泛化问题。但是,尽管它们可以改进当前人工智能系统的结果,但它们并不能解决跨视点泛化的根本问题。总会有新的角度、新的照明条件、新的颜色和姿势,而这些新的数据集并不能包含所有这些情况。这些新情况甚至会使最大、最先进的人工智能系统陷入混乱。
差异可能是危险的
从上面提出的观点来看,卷积神经网络(CNNs)显然是以与人类截然不同的方式来识别物体的。但是,这些差异不仅在弱泛化上存在局限,而且还需要更多的示例来学习一个对象。卷积神经网络生成对象的内部表示形式也与人脑的生物神经网络非常不同。
这是如何表现出来的?“我可以拍摄一张照片,再加上一点点噪点,卷积神经网络就会将其识别为完全不同的东西,而我本人几乎看不出它们有什么不同。这似乎真的很奇怪,我认为这是证据,卷积神经网络实际上是在使用与我们完全不同的信息来识别图像。” Hinton在AAAI会议上的主题演讲中说道。
这些稍加修改的图像被称为“对抗性样本 ”,是人工智能领域的研究热点。
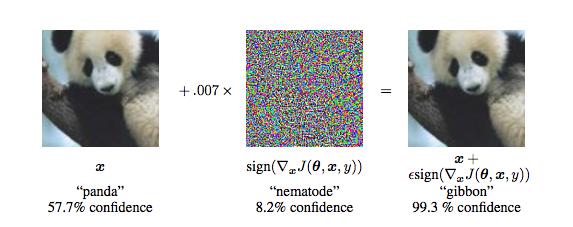
对抗性样本可能会导致神经网络对图像进行错误分类,而对人眼却没有影响。
Hinton说:“并不是说这是错的,他们只是使用一种完全不同的方式来工作,而且他们这种完全不同的做法在如何泛化方面也会有一些不同。”。
但是许多例子表明,对抗性干扰可能是极其危险的。当你的图像分类器错误地将熊猫标记为长臂猿时,这一切都是可爱和有趣的。但是,当自动驾驶汽车的计算机视觉系统缺少了一个停车标志时,而绕过面部识别安全系统的邪恶黑客,或者谷歌照片将人类标记为大猩猩时,你就会有大麻烦了。
关于检测对抗性扰动 并创建可抵抗对抗性扰动的强大的人工智能系统 ,已经有很多研究。但是,对抗性样本也提醒我们:我们的视觉系统经过几代人的进化,已经能够处理我们周围的世界,我们也创造了我们的世界来适应我们的视觉系统。因此,如果我们的计算机视觉系统以与人类视觉根本不同的方式工作,它们将是不可预测且不可靠的,除非它们得到诸如激光雷达和雷达测绘等补充技术的支持。
坐标系和部分-整体关系很重要
Geoffrey Hinton在AAAI大会的主题演讲中指出的另一个问题是,卷积神经网络无法从对象及其部分的角度来理解图像。它们将图像识别为以不同图案排列的像素斑点。它们也没有实体及其关系的显式内部表示。
“当你将卷积神经网络想象成各个像素位置的中心时,你会越来越丰富地描述该像素位置上发生的事情,这取决于越来越多的上下文。最后,你获得了如此丰富的描述,以至于你知道图像中存在哪些对象。但是它们并没有明确地解析图像。”Hinton说。
我们对物体构成的理解有助于我们了解这个世界,并理解我们以前从未见过的东西,比如这个奇特的茶壶。
将对象分解为多个部分有助于我们了解其性质。这是马桶还是茶壶?(资源来源:Smashing lists)
卷积神经网络中还缺少坐标系,这是人类视觉的基本组成部分。基本上,当我们看到一个物体时,我们开发了一个关于它的方向的心理模型,这有助于我们解析它的不同特征。例如,在下图中,考虑右边的脸。如果你将其倒置,你会看到左边的脸。但实际上,你不需要物理翻转图像就可以看到左边的脸。只需在精神上调整坐标系,就可以看到两个面,无论图像的方向如何。
Hinton指出:“根据所施加的坐标系,你会有完全不同的内部感知。卷积神经网络确实不能解释这一点。你给他们一个输入,他们就有一个感知,而感知并不依赖于强加的坐标系。我想,这与对抗性样本有关,也与卷积神经网络以与人完全不同的方式进行感知这一事实有关。”
从计算机图形学中吸取教训
Hinton在AAAI会议上的演讲中指出,解决计算机视觉的一种非常简便的方法是制作逆向图。三维计算机图形模型是由对象的层次结构组成的。每个对象都有一个转换矩阵,该矩阵定义了其相对于其父对象的平移,旋转和缩放比例。每个层次结构中顶级对象的变换矩阵定义了其相对于世界原点的坐标和方向。
例如,考虑汽车的3D模型。基础对象具有4×4变换矩阵,该矩阵表示汽车的中心位于具有旋转(X = 0,Y = 0,Z = 90)的坐标(X = 10,Y = 10,Z = 0)处 。汽车本身由许多对象组成,如车轮、底盘、方向盘、挡风玻璃、变速箱、发动机等。每个对象都有自己的变换矩阵,以父矩阵(汽车的中心)为参照,它们定义了自己的位置和方向。例如,左前轮的中心位于(X=-1.5,Y=2,Z=-0.3)。左前轮的世界坐标可以通过将其变换矩阵与其父矩阵相乘得到。
其中一些对象可能具有自己的子集。例如,车轮由轮胎,轮辋,轮毂,螺母等部件组成。这些子项中的每一个都有自己的变换矩阵。
使用这种坐标系层次结构,可以非常轻松地定位和可视化对象,而不管它们的姿势、方向或视点如何。当你要渲染对象时,将3D对象中的每个三角形乘以其变换矩阵及其父对象的变换矩阵。然后将其与视点对齐(另一个矩阵乘法),然后在栅格化为像素之前转换为屏幕坐标。
“如果你(对从事计算机图形学工作的人)说:‘你能从另一个角度向我展示吗?’他们不会说,‘哦,好吧,我很乐意。但是我们没有从那个角度进行训练,所以我们无法从那个角度向你展示。’他们只是从另一个角度向你展示,因为他们有一个3D模型,他们依据部分和整体之间的关系对一个空间结构进行建模,而这些关系根本不依赖于视点。”Hinton说。“我觉得在处理3D对象的图像时,不利用这种漂亮的结构是很疯狂的。”
胶囊网络(Capsule Network),是Hinton的另一个雄心勃勃的新项目,它尝试制作逆向计算机图形。尽管胶囊网络应该有自己独立的一套东西,但其背后的基本思想也是拍摄图像,提取其对象及其部分,定义其坐标系,并创建图像的模块化结构。
胶囊网络仍在研发中,自2017年推出以来,它们已经经历了多次迭代。但是,如果Hinton和他的同事们能够成功地使他们发挥作用,我们将更接近复制人类的视觉。
本文为 CSDN 翻译,转载请注明来源出处。游戏网
编后语:关于《理解AI最伟大的成就之一:卷积神经网络的局限性》关于知识就介绍到这里,希望本站内容能让您有所收获,如有疑问可跟帖留言,值班小编第一时间回复。 下一篇内容是有关《iPhoneSE预售超40万,价格破发直降500,销量吊打华为P40!》,感兴趣的同学可以点击进去看看。




























































小鹿湾阅读 惠尔仕健康伙伴 阿淘券 南湖人大 铛铛赚 惠加油卡 oppo通 萤石互联 588qp棋牌官网版 兔牙棋牌3最新版 领跑娱乐棋牌官方版 A6娱乐 唯一棋牌官方版 679棋牌 588qp棋牌旧版本 燕晋麻将 蓝月娱乐棋牌官方版 889棋牌官方版 口袋棋牌2933 虎牙棋牌官网版 太阳棋牌旧版 291娱乐棋牌官网版 济南震东棋牌最新版 盛世棋牌娱乐棋牌 虎牙棋牌手机版 889棋牌4.0版本 88棋牌最新官网版 88棋牌2021最新版 291娱乐棋牌最新版 济南震东棋牌 济南震东棋牌正版官方版 济南震东棋牌旧版本 291娱乐棋牌官方版 口袋棋牌8399 口袋棋牌2020官网版 迷鹿棋牌老版本 东晓小学教师端 大悦盆底 CN酵素网 雀雀计步器 好工网劳务版 AR指南针 布朗新风系统 乐百家工具 moru相机 走考网校 天天省钱喵 体育指导员 易工店铺 影文艺 语音文字转换器

