欢迎来到noYes游戏王国
网站导航
在上一篇文章中,小编为您详细介绍了关于《小店转型亟待加速》相关知识。本篇中小编将再为您讲解标题微软计算机视觉创研论坛首日干货:3项前沿检测技术解读。
原标题:微软计算机视觉创研论坛首日干货:3项前沿检测技术解读

智东西(公众号:zhidxcom)
编 | 董温淑
智东西5月15日消息,昨日上午9点,微软亚洲研究院创研论坛CVPR 2020论文分享会线上开幕。会议有19位计算机视觉(CV)领域学者分享最新研究成果,讲解内容涉及检测、多模态、底层视觉、图像生成、机器学习5大方向。
14日上午,3位计算机视觉检测方向的研究员做了分享,分别介绍了先进的人脸识别技术、动作检测技术和目标检测技术。智东西对这3项先进技术进行解读。
微软亚洲研究院创研论坛CVPR 2020论文分享会是计算机视觉(CV)领域最重要的会议之一,本届会议共分享近20项CV领域前沿技术。
一、X射线检测算法识别假图像,准确率可达95.4%
Deepfake技术的滥用轻则造成虚假信息问题,重则会引起金融安全风险、侵权问题等。一些Deepfake图像可以做到以假乱真,人类肉眼难以判断出来。这种情况下,人脸识别技术可以帮我们辨别。
现有的人脸识别工具大多针对某种特定Deepfake技术训练,用假人脸图像作为输入。就是说,人脸识别技术只能识别出特定方法合成的假图像。一旦Deepfake技术进化或换用其他Deepfake技术,人脸识别模型就可能失效。
微软亚洲研究院研究员鲍建敏讲解了人脸X射线识别技术(Face X-ray),这种技术用真实人脸图像进行训练。即使Deepfake技术进化,X射线人脸检测算法也能保持较高的准确性。
制作一张假图像的方法是把两张图像叠加,即把一张修改过的人脸图像(前景)合成到背景图像(后景)中。研究人员注意到,由于每张图像拍摄或制作过程中用到不同的硬件(传感器、透镜等)或软件(压缩、合成算法等),前景图像和后景图像的特征不可能完全相同,因此人脸图像和背景图像之间存在一个“边界”。
Face X-ray技术利用了上述特征,用人脸灰度图像作为输入。Face X-ray模型可以识别出不同灰度图像之间的差异,这样不仅可以显示出人脸图像是真实的还是伪造的,还能确定虚假图像混合边界的位置。

▲左起第一张为真实图像,其他均为假图像,Face X-ray模型检测出了假图像混合边界位置。
研究人员对比了Face X-ray模型与之前人脸识别工具的性能。结果显示,模型检测出来的假脸帧数比之前的二分类方法更多,识别准确率最高可达95.4%。
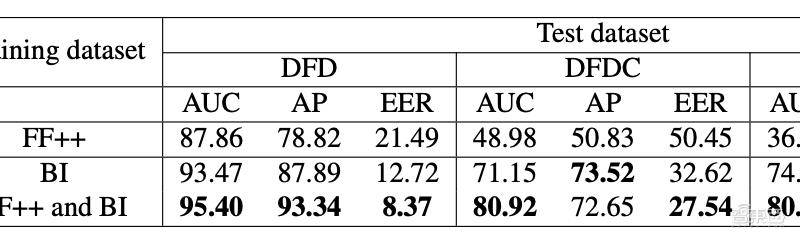
鲍建敏指出,算法还有一定局限性。比如,Face X-ray主要用人脸图像数据库FF++进行训练。FF++中大部分图像都是正脸图像,所以模型识别侧脸的准确性较低。
二、DAGM模型:区分动作与上下文,准确识别出动作
微软亚洲研究院研究员戴琦讲解了一种动作检测技术,该技术可以从视频中识别出动作。据了解,目前的动作检测技术可以分为全监督方法和弱监督方法。
全监督方法的动作检测模型需要在训练过程中需要对动作间隔进行时间注释,十分昂贵和费时。因此现有的动作检测工具多采用弱监督动作定位(WSAL,weakly-supervised action localization)技术。
WSAL技术有两种类型,第一类建立一个从上到下的管道,学习一个视频级别的分类器,通过检查生成的时间分类动作地图(TACM,temporal class activation map)来获得帧注意力(frame attention)。第二类是从下到上的,直接从原始数据中预测时间注意力(temporal attention),然后从视频级监控的视频分类中优化任务。
两种方法都依赖于视频级别的分类模型,这会导致动作和上下文混淆(action-context confusion)的问题。比如,在一段跳远的视频中,跳远动作(action)仅包括接近、跳跃、着陆3个阶段,但是工作检测模型常把准备和结束阶段(context)也选中。

研究人员认为,解决这一问题的关键在于找到动作和上下文之间的区别。他们用判别性注意力模型(Discriminative Attention Modeling)和生成性注意力模型(GAM,Generative Attention Modeling)优化检测工具,提出了判别性和生成性注意力模型(DAGM,Discriminative and Gener-ative Attention Modeling)。
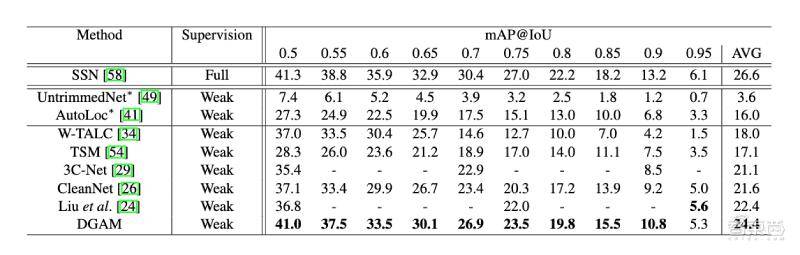
研究人员对比了DAGM模型与其他弱监督动作工具的性能。结果显示,DAGM模型的性能较好,平均精度最高可达41。
三、TSD算法:把检测工具精度提高3~5%
目标识别算法一般从两个维度检测物体:分类(Classification)和回归(Localization)。前者指识别物体的属性,后者指定位物体的位置。
传统检测方法通常一起学习分类和回归,共享物体潜在存在的区域框(Proposal)和特征提取器(Sibling head)。
这种检测方法的局限性是最终输出的图片框的分类置信度和检测框的准确度不一致,识别准确率较低。
研究人员发现,这是因为分类任务和回归任务存在差别:分类任务更关注语义信息丰富的地方,回归任务更关注物体的边界。因此,共享物体潜在存在的区域框(Proposal)和特征提取器(Sibling head)会对检测结果造成影响。
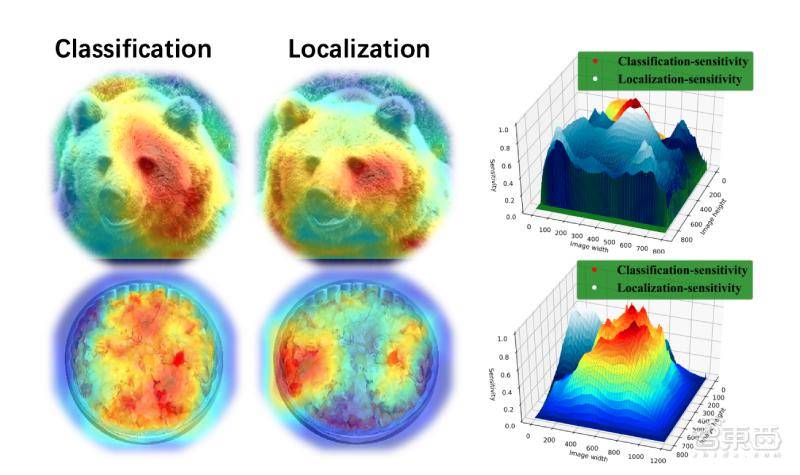
商汤科技X-Lab研究员宋广录介绍了基于任务间空间自适应解耦(TSD,task-aware spatial disentanglement)检测算法,即在检测器头部应用特定设计的偏移量生成策略以及联合训练优化渐进损失。结果显示,搭配TSD算法的检测工具的检测精度能提高3~5%。
结语:CV研究面临语义、鲁棒性的挑战
三位研究人员分享结束后,美国罗彻斯特大学罗杰波教授、加州大学伯克利分校马毅教授、加州大学圣地亚哥分校屠卓文教授、美国加州大学杨明玄教授、Wormpex AI Research华刚教授进行了圆桌论坛。这5位教授都曾担任过CVPR会议主席。
在题目选择、写作技巧方面,5位教授对CV研究者给出许多建议,比如,他们认为研究者不必盲目追求研究热点,而应该选择自己感兴趣的题目;刚刚起步的研究者可以借鉴成熟研究者的论文结构。他们强调,论文预印本网站arXiv上的论文质量良莠不齐,研究者在借鉴时应该注意甄别。
另外,5位教授指出,目前CV研究面临的两大主要挑战来自语义和鲁棒性。对语义的理解关系着模型能否完成更高级别的任务。在医疗、无人机、航空航天等领域中,CV模型的鲁棒性直接影响到安全。
因此,在之后的CV研究中,提升CV模型对语义的理解能力和鲁棒性仍是重点。游戏网
编后语:关于《微软计算机视觉创研论坛首日干货:3项前沿检测技术解读》关于知识就介绍到这里,希望本站内容能让您有所收获,如有疑问可跟帖留言,值班小编第一时间回复。 下一篇内容是有关《SK与三星合作发布首款集成了量子随机数发生器芯片5G智能手机GalaxyAQuantum》,感兴趣的同学可以点击进去看看。




























































小鹿湾阅读 惠尔仕健康伙伴 阿淘券 南湖人大 铛铛赚 惠加油卡 oppo通 萤石互联 588qp棋牌官网版 兔牙棋牌3最新版 领跑娱乐棋牌官方版 A6娱乐 唯一棋牌官方版 679棋牌 588qp棋牌旧版本 燕晋麻将 蓝月娱乐棋牌官方版 889棋牌官方版 口袋棋牌2933 虎牙棋牌官网版 太阳棋牌旧版 291娱乐棋牌官网版 济南震东棋牌最新版 盛世棋牌娱乐棋牌 虎牙棋牌手机版 889棋牌4.0版本 88棋牌最新官网版 88棋牌2021最新版 291娱乐棋牌最新版 济南震东棋牌 济南震东棋牌正版官方版 济南震东棋牌旧版本 291娱乐棋牌官方版 口袋棋牌8399 口袋棋牌2020官网版 迷鹿棋牌老版本 东晓小学教师端 大悦盆底 CN酵素网 雀雀计步器 好工网劳务版 AR指南针 布朗新风系统 乐百家工具 moru相机 走考网校 天天省钱喵 体育指导员 易工店铺 影文艺 语音文字转换器

