欢迎来到noYes游戏王国
网站导航
在上一篇文章中,小编为您详细介绍了关于《千古传说KU25《花千骨》一起浪漫江湖行》相关知识。本篇中小编将再为您讲解标题工程之道:旷视天元框架亚线性显存优化技术解析。
原标题:工程之道:旷视天元框架亚线性显存优化技术解析
机器之心发布
旷视研究院
基于梯度检查点的亚线性显存优化方法 [1] 由于较高的计算/显存性价比受到关注。MegEngine 经过工程扩展和优化,发展出一套行之有效的加强版亚线性显存优化技术,既可在计算存储资源受限的条件下,轻松训练更深的模型,又可使用更大 batch size,进一步提升模型性能,稳定 batchwise 算子。使用 MegEngine 训练 ResNet18/ResNet50,显存占用分别最高降低 23%/40%;在更大的 Bert 模型上,降幅更是高达 75%,而额外的计算开销几乎不变。

深度神经网络训练是一件复杂的事情,它体现为模型的时间复杂度和空间复杂度,分别对应着计算和内存;而训练时内存占用问题是漂浮在深度学习社区上空的一块乌云,如何拨云见日,最大降低神经网络训练的内存占用,是一个绕不开的课题。
GPU 显卡等硬件为深度学习提供了必需的算力,但硬件自身有限的存储,限制了可训练模型的尺寸,尤其是大型深度网络,由此诞生出一系列相关技术,比如亚线性显存优化、梯度累加、混合精度训练、分布式训练,进行 GPU 显存优化。
其中,亚线性显存优化方法 [1] 由于较高的计算/显存性价比备受关注;旷视基于此,经过工程扩展和优化,发展出加强版的 MegEngine 亚线性显存优化技术,轻松把大模型甚至超大模型装进显存,也可以毫无压力使用大 batch 训练模型。
这里将围绕着深度学习框架 MegEngine 亚线性显存优化技术的工程实现和实验数据,从技术背景、原理、使用、展望等多个方面进行首次深入解读。
背景
在深度学习领域中,随着训练数据的增加,需要相应增加模型的尺寸和复杂度,进行模型「扩容」;而 ResNet [2] 等技术的出现在算法层面扫清了训练深度模型的障碍。不断增加的数据和持续创新的算法给深度学习框架带来了新挑战,能否在模型训练时有效利用有限的计算存储资源,尤其是减少 GPU 显存占用,是评估深度学习框架性能的重要指标。
在计算存储资源一定的情况下,深度学习框架有几种降低显存占用的常用方法,其示例如下:
上述显存优化技术在 MegEngine 中皆有不同程度的实现,这里重点讨论基于梯度检查点的亚线性显存优化技术。
原理
一个神经网络模型所占用的显存空间大体分为两个方面:1)模型本身的参数,2)模型训练临时占用的空间,包括参数的梯度、特征图等。其中最大占比是 2)中以特征图形式存在的中间结果,比如,从示例 [1] 可知,根据实现的不同,从 70% 到 90% 以上的显存用来存储特征图。
这里的训练过程又可分为前向计算,反向计算和优化三个方面,其中前向计算的中间结果最占显存,还有反向计算的梯度。第 1)方面模型自身的参数内存占用最小。
MegEngine 加强版亚线性显存优化技术借鉴了 [1] 的方法,尤其适用于计算存储资源受限的情况,比如一张英伟达 2080Ti,只有 11G 的显存;而更贵的 Tesla V100,最大显存也只有 32G。
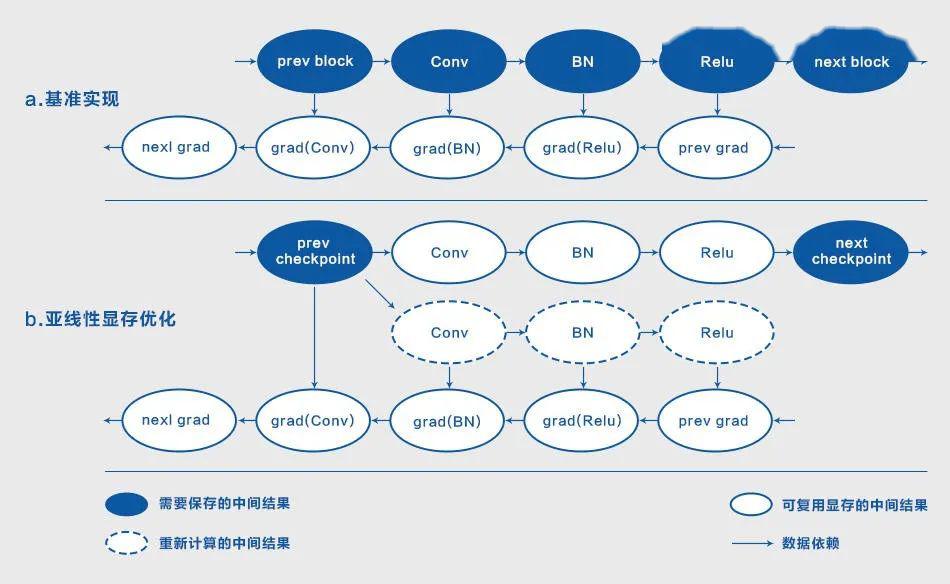
图 1:亚线性显存优化原理,其中 (b) 保存了 Relu 结果,实际中 Relu 结果可用 in-place 计算
图 1(a) 给出了卷积神经网络的基本单元,它由 Conv-BN-Relu 组成。可以看到,反向计算梯度的过程依赖于前向计算获取的中间结果,一个网络需要保存的中间结果与其大小成正比,即显存复杂度为 O(n)。
本质上,亚线性显存优化方法是以时间换空间,以计算换显存,如图 1(b) 所示,它的算法原理如下:
这种方法有着明显的优点,即大幅降低了模型的空间复杂度,同时缺点是增加了额外的计算:
工程
在 [1] 的基础上,MegEngine 结合自身实践,做了工程扩展和优化,把亚线性显存优化方法扩展至任意的计算图,并结合其它常见的显存优化方法,发展出一套行之有效的加强版亚线性显存优化技术。
亚线性优化方法采用简单的网格搜索(grid search)选择检查点,MegEngine 在此基础上增加遗传算法,采用边界移动、块合并、块分裂等策略,实现更细粒度的优化,进一步降低了显存占用。
如图 2 所示,采用型号为 2080Ti 的 GPU 训练 ResNet50,分别借助基准、亚线性、亚线性+遗传算法三种显存优化策略,对比了可使用的最大 batch size。仅使用亚线性优化,batch size 从 133 增至 211,是基准的 1.6x;而使用亚线性+遗传算法联合优化,batch size 进一步增至 262,较基准提升 2x。
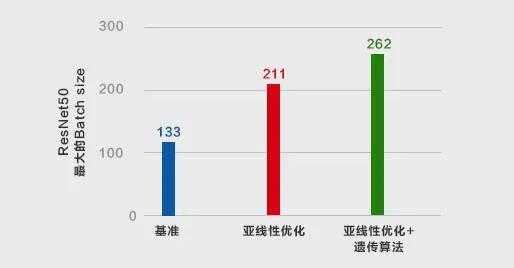
图 2:三种显存优化方法优化 batch size 的对比:ResNet50
通过选定同一模型、给定 batch size,可以更好地观察遗传算法优化显存占用的情况。如图 3 所示,随着迭代次数的增加,遗传算法逐渐收敛显存占用,并在第 5 次迭代之后达到一个较稳定的状态。
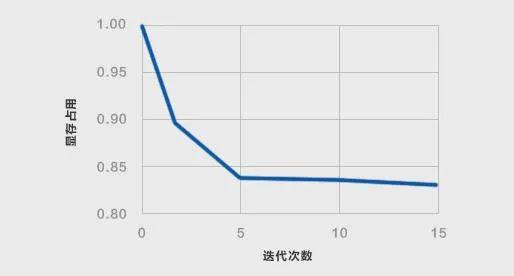
图 3:遗传算法收敛示意图
此外,MegEngine 亚线性优化技术通过工程改良,不再局限于简单的链状结构和同质计算节点, 可用于任意的计算图,计算节点也可异质,从而拓展了技术的适用场景;并可配合上述显存优化方法,进一步降低模型的显存占用。
实验
MegEngine 基于亚线性显存技术开展了相关实验,这里固定 batch size=64,在 ResNet18 和 ResNet50 两个模型上,考察模型训练时的显存占用和计算时间。
如图 4 所示,相较于基准实现,使用 MegEngine 亚线性显存技术训练 ResNet18 时,显存占用降低 32%,计算时间增加 24%;在较大的 ReNet50 上,显存占用降低 40%,计算时间增加 25%。同时经过理论分析可知,模型越大,亚线性显存优化的效果越明显,额外的计算时间则几乎不变。
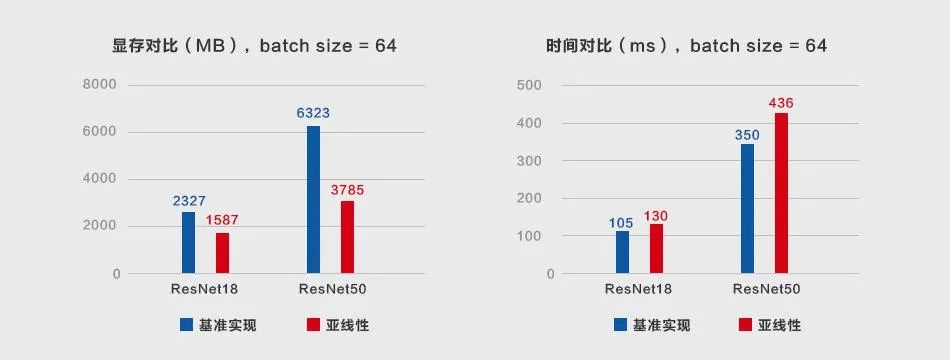
图 4:MegEngine 亚线性优化技术实验显存/时间对比:ReNet18/ReNet50
在更大模型 Bert 上实验数据表明,借助 MegEngine 亚线性显存技术,显存占用最高降低 75%,而计算时间仅增加 23%,这与理论分析相一致。有兴趣的同学可前往 MegEngine ModeHub 试手更多模型实验:https://megengine.org.cn/model-hub/。
使用
MegEngine 官网提供了亚线性显存优化技术的使用文档。当你的 GPU 显存有限,苦于无法训练较深、较大的神经网络模型,或者无法使用大 batch 进一步提升深度神经网络的性能,抑或想要使 batchwise 算子更加稳定,那么,MegEngine 亚线性显存优化技术正是你需要的解决方案。
上手 MegEngine 亚线性优化技术非常便捷,无需手动设定梯度检查点,通过几个简单的参数,轻松控制遗传算法的搜索策略。具体使用时,在 MegEngine 静态图接口中调用 SublinearMemoryConfig 设置 trace 的参数 sublinear_memory_config,即可打开亚线性显存优化:
config = SublinearMemoryConfig
@trace(symbolic=True, sublinear_memory_config=config)def train_func(data, label, *, net, optimizer):...
MegEngine 在编译计算图和训练模型时,虽有少量的额外时间开销,但会显著缓解显存不足问题。下面以 ResNet50 为例,说明 MegEngine 可有效突破显存瓶颈,训练 batch size 从 100 最高增至 200:
def train_resnet_demo(batch_size, enable_sublinear, genetic_nr_iter=0):import megengine as mgeimport megengine.functional as Fimport megengine.hub as hubimport megengine.optimizer as optimfrom megengine.jit import trace, SublinearMemoryConfigimport numpy as np
print("Run with batch_size={}, enable_sublinear={}, genetic_nr_iter={}".format(batch_size, enable_sublinear, genetic_nr_iter))# 使用GPU运行这个例子assert mge.is_cuda_available, "Please run with GPU"try:# 我们从 megengine hub 中加载一个 resnet50 模型。resnet = hub.load("megengine/models", "resnet50")
optimizer = optim.SGD(resnet.parameters, lr=0.1,)
config = Noneif enable_sublinear:config = SublinearMemoryConfig(genetic_nr_iter=genetic_nr_iter)
@trace(symbolic=True, sublinear_memory_config=config)def train_func(data, label, *, net, optimizer):pred = net(data)loss = F.cross_entropy_with_softmax(pred, label)optimizer.backward(loss)
resnet.trainfor i in range(10):batch_data = np.random.randn(batch_size, 3, 224, 224).astype(np.float32)batch_label = np.random.randint(1000, size=(batch_size,)).astype(np.int32)optimizer.zero_gradtrain_func(batch_data, batch_label, net=resnet, optimizer=optimizer)optimizer.stepexcept:print("Failed")return
print("Sucess")
# 以下示例结果在2080Ti GPU运行得到,显存容量为 11 GB
# 不使用亚线性内存优化,允许的batch_size最大为 100 左右p = Process(target=train_resnet_demo, args=(100, False))p.startp.join# 报错显存不足p = Process(target=train_resnet_demo, args=(200, False))p.startp.join
# 使用亚线性内存优化,允许的batch_size最大为 200 左右p = Process(target=train_resnet_demo, args=(200, True, 20))p.startp.join
展望
如上所述,MegEngine 的亚线性显存优化技术通过额外做一次前向计算,即可达到 O(sqrt(n)) 的空间复杂度。如果允许做更多次的前向计算,对整个网络递归地调用亚线性显存算法,有望在时间复杂度为 O(n log n) 的情况下,达到 O(log n) 的空间复杂度。
更进一步,MegEngine 还将探索亚线性显存优化技术与数据并行/模型并行、混合精度训练的组合使用问题,以期获得更佳的集成效果。最后,在 RNN 以及 GNN、Transformer 等其他类型网络上的使用问题,也是 MegEngine 未来的一个探索方向。
欢迎访问
参考文献
1.Chen, T., Xu, B., Zhang, C., & Guestrin, C. (2016). Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174.
2.He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
本 文为机器之心发布, 转载请联系本公众号获得授权 。游戏网
编后语:关于《工程之道:旷视天元框架亚线性显存优化技术解析》关于知识就介绍到这里,希望本站内容能让您有所收获,如有疑问可跟帖留言,值班小编第一时间回复。 下一篇内容是有关《《火线精英》一刀999系兄弟就来锤我》,感兴趣的同学可以点击进去看看。




























































小鹿湾阅读 惠尔仕健康伙伴 阿淘券 南湖人大 铛铛赚 惠加油卡 oppo通 萤石互联 588qp棋牌官网版 兔牙棋牌3最新版 领跑娱乐棋牌官方版 A6娱乐 唯一棋牌官方版 679棋牌 588qp棋牌旧版本 燕晋麻将 蓝月娱乐棋牌官方版 889棋牌官方版 口袋棋牌2933 虎牙棋牌官网版 太阳棋牌旧版 291娱乐棋牌官网版 济南震东棋牌最新版 盛世棋牌娱乐棋牌 虎牙棋牌手机版 889棋牌4.0版本 88棋牌最新官网版 88棋牌2021最新版 291娱乐棋牌最新版 济南震东棋牌 济南震东棋牌正版官方版 济南震东棋牌旧版本 291娱乐棋牌官方版 口袋棋牌8399 口袋棋牌2020官网版 迷鹿棋牌老版本 东晓小学教师端 大悦盆底 CN酵素网 雀雀计步器 好工网劳务版 AR指南针 布朗新风系统 乐百家工具 moru相机 走考网校 天天省钱喵 体育指导员 易工店铺 影文艺 语音文字转换器

