欢迎来到noYes游戏王国
网站导航
在上一篇文章中,小编为您详细介绍了关于《iPhone用户请注意:你的邮件App得禁用,刚曝光的安全漏洞,iOS6以上设备全中招》相关知识。本篇中小编将再为您讲解标题ICLR2020|MIT、DeepMind等联合发布CLEVRER数据集,推动视频理解的因果逻辑推理。
原标题:ICLR 2020 | MIT、DeepMind等联合发布CLEVRER数据集,推动视频理解的因果逻辑推理
机器之心发布

从视频的物理事件中识别物体并推断其运动轨迹的能力是人类认知发展的核心。人类,即使是幼儿,也能够通过运动将图片区域划分为多个物体,并使用物体的永久性、实体性和连贯性的概念来解释发生了什么,推断将发生什么以及想象在反事实情况下会发生什么。
在静态图像和视频上提出的各种数据集的推动下,复杂视觉推理问题已经在人工智能和计算机视觉领域得到了广泛研究。然而,大多数视频推理数据集的侧重点是从复杂的视觉和语言输入中进行模式识别,而不是基于因果结构。尽管这些数据集涵盖了视觉的复杂性和多样性,但推理过程背后的基本逻辑、时间和因果结构却很少被探索。
在这篇论文中,麻省理工和 DeepMind 的研究者从互补的角度研究了视频中的时间和因果推理问题。受视觉推理数据集 CLEVR 的启发,他们简化了视觉识别问题,但增强了交互对象背后的时间和因果结构的复杂度。结合从发展心理学中汲取的灵感,他们提出了一种针对时间和因果推理问题的数据集。
CLEVRER
研究者将这个数据集称为基于碰撞事件的视频推理(CLEVRER)。CLEVRER 的设计遵循两个准则:首先,发布的任务应侧重于在时间和因果上的逻辑推理,同时,保持简单以及在视觉场景和语言上出现的偏差最小;其次,数据集应完全可控并正确标注,以承载复杂的视觉推理任务并为模型提供有效的评估。
CLEVRER 包含 20,000 个关于碰撞物体的合成视频以及 300,000 多个问题和答案。问题的类型包括以下四种,如下图所示:

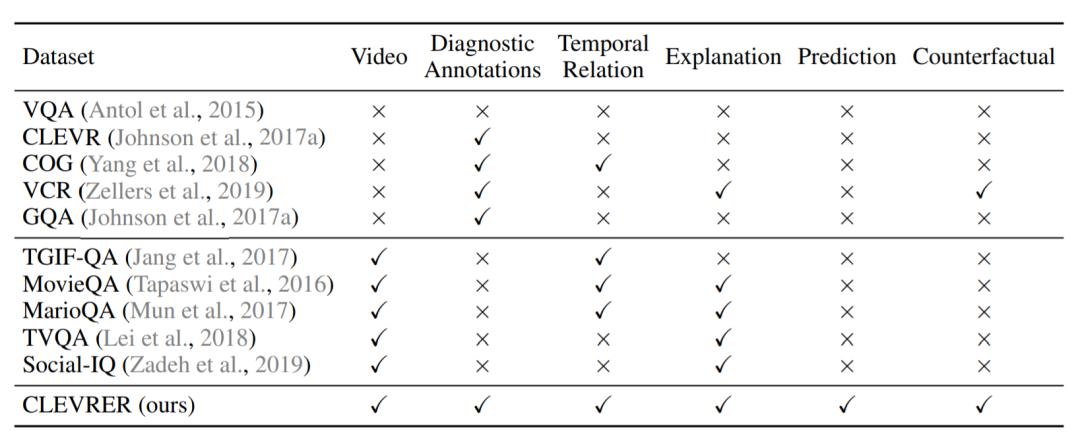
CLEVRER 附带有视频中每个对象的真实运动轨迹和事件历史记录。每个问题都与代表其基本逻辑的程序匹配。如下表所示,CLEVRER 在多个方面补充了现有的视觉推理数据集,并引入了一些新颖的任务。
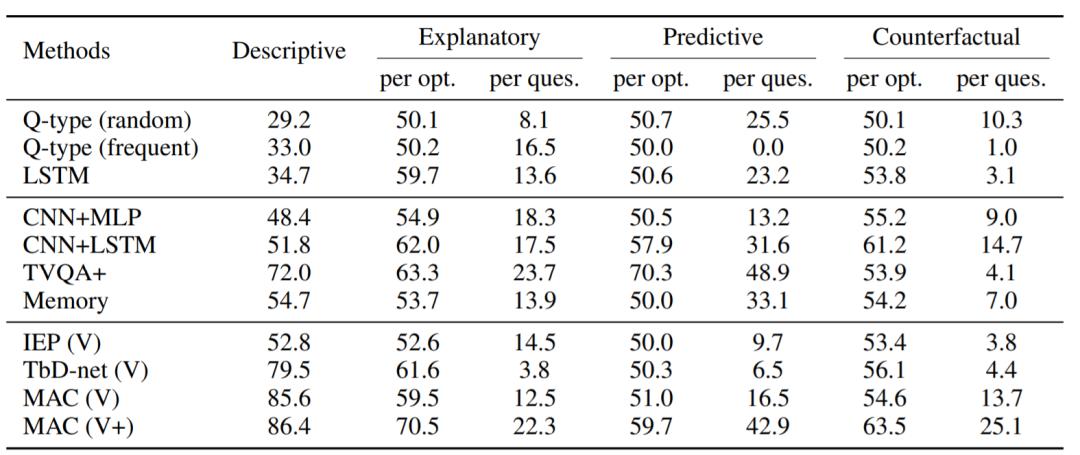
研究者对各种最新的视觉推理模型在 CLEVRER 上进行了评估,结果如下表所示。尽管这些模型在描述性问题上表现良好,但它们缺乏因果推理的能力,在解释性,预测性和反事实问题上表现不佳。
他们认为视觉推理任务包含三个关键要素:视频中的物体和事件的识别;物体与事件之间动力学和因果关系的建模;理解问题背后的符号逻辑。作为对此原理的初步探索,他们提出了一种新的预测模型——结合神经网络和符号表征的动态推理(NS-DR),通过视频符号表征将这些要素明确地联结在一起。
NS-DR 模型
NS-DR 模型结合了用于模式识别和动力学预测的神经网络,以及用于因果推理的符号逻辑。如下图所示,NS-DR 模型由视频解析器(Ⅰ)、动态预测器(Ⅱ)、问题解析器(Ⅲ)和程序执行器组成(Ⅳ)。
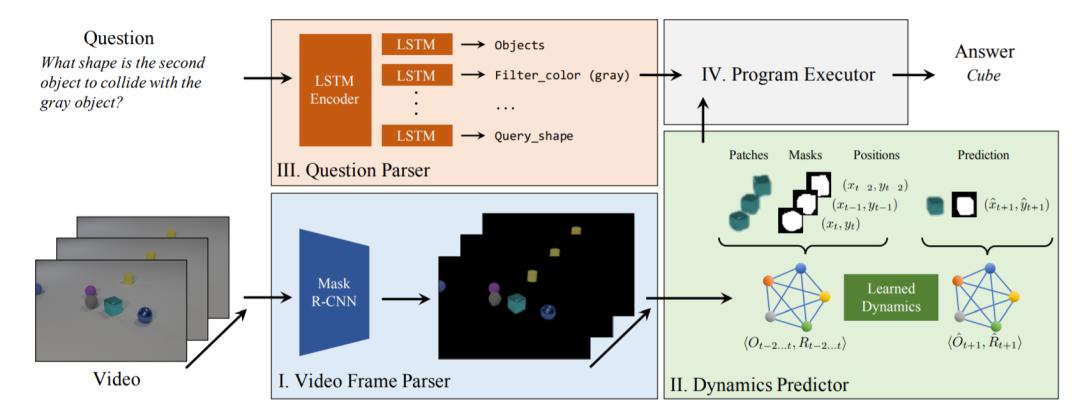
视频解析器
研究者使用 ResNet-50 FPN 作为主干网络,通过 Mask R-CNN 在每帧视频上执行物体检测和场景去渲染。对于输入的每帧视频,网络输出物体的固有属性(颜色、材料、形状)标签、物体的 mask proposals 以及 proposal 的置信度,由此获得以物体为中心的视频表征。
动态预测器
他们将 PropNet 应用到动态建模中,将物体的 proposals 作为输入,预测其运动轨迹和碰撞事件。
PropNet 将动态系统表示为有向图 G=〈O,R〉,其中顶点 O={o_i } 表示物体,边 R={r_k } 表示关系。每个物体 o_i 和关系 r_k 可以进一步写成
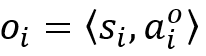
,,其中 s_i 表示物体的状态;表示物体的固有属性;u_k 和 v_k 表示由边 r_k 连接的接收方和发送方顶点的索引;表示边的状态,即两个物体之间是否存在碰撞。PropNet 通过多步信息传递来处理物体之间的状态转移。
问题解析器
使用基于注意力机制的 Seq2Seq 模型将输入的问题解析为相应的程序,模型由双向 LSTM 编码器和注意力 LSTM 解码器组成。给定输入单词序列,编码器首先在每个步骤生成双向潜在编码
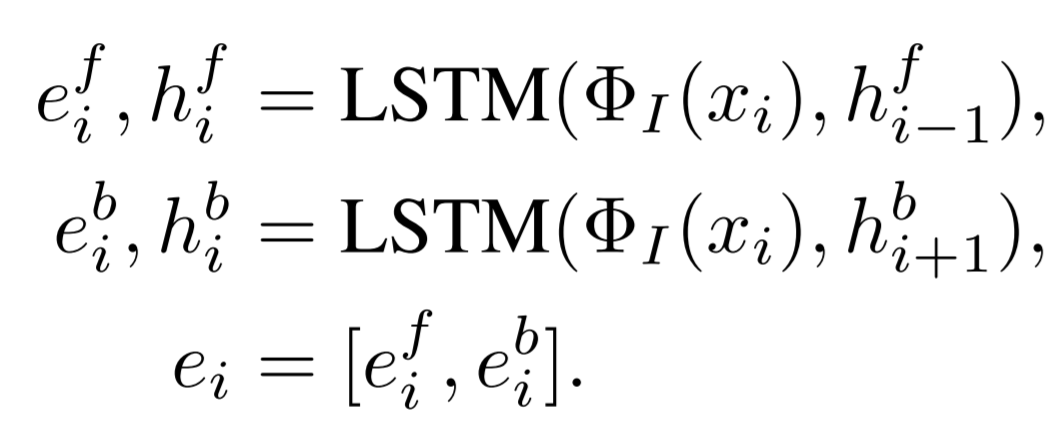
然后,解码器使用注意力机制从潜在编码中生成一系列程序 token:
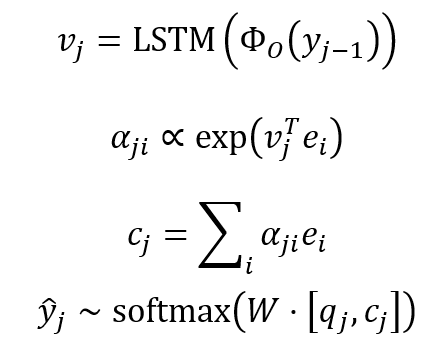
其中,编码器和解码器均使用两层隐藏层和 300 维度单词嵌入向量。
程序执行器
程序执行器在动态预测器提取的运动轨迹和碰撞事件上执行程序,并输出问题的答案。它包含多个通过 Python 实现的程序模块,其中共有三种类型:输入模块,过滤器模块和输出模块。输入模块是程序树的入口点;过滤器模块基于固有属性、运动状态、时间顺序或因果关系对输入物体/事件执行逻辑运算;输出模块返回答案标签。
NS-DR 性能评估
研究者在 CLEVRER 上评估了 NS-DR 的性能,结果如下表所示。对于描述性问题,他们的模型可达到 88.1%的准确率,显著优于其他基准方法。在解释性、预测性和反事实问题上,他们的模型获得了更大的提升。

NS-DR 将动态规划纳入视觉推理任务中,能够直接对未观察到的运动和事件进行预测,并能够对预测性和反事实性任务进行建模。这表明动态规划对基于语言的视觉推理任务具有很大的潜力,NS-DR 朝着这个方向迈出了初步探索。此外,符号表征为视觉、语言、动力学和因果关系提供了强大的共同基础。通过设计,它使模型能够明确地捕获视频因果结构和问题逻辑。
总结
视频中时间和因果推理,这个深刻且具有挑战性的问题已深深植根于人工智能的基础之上,最近才开始使用「现代」人工智能方法进行研究。他们引入了一系列基准任务,以更好地促进这一领域的研究,新提出的 CLEVRER 数据集和 NS-DR 模型是朝着这个方向迈出的初步尝试。
研究者希望随着图网络、视觉预测模型和结合神经网络和符号表征算法的最新发展,深度学习领域可以在将来更加现实的设置中重新审视这一经典问题,从而获得超越模式识别的真正智能。游戏网
编后语:关于《ICLR2020|MIT、DeepMind等联合发布CLEVRER数据集,推动视频理解的因果逻辑推理》关于知识就介绍到这里,希望本站内容能让您有所收获,如有疑问可跟帖留言,值班小编第一时间回复。 下一篇内容是有关《我今年24岁,即将失明,还能继续写代码吗?》,感兴趣的同学可以点击进去看看。




























































小鹿湾阅读 惠尔仕健康伙伴 阿淘券 南湖人大 铛铛赚 惠加油卡 oppo通 萤石互联 588qp棋牌官网版 兔牙棋牌3最新版 领跑娱乐棋牌官方版 A6娱乐 唯一棋牌官方版 679棋牌 588qp棋牌旧版本 燕晋麻将 蓝月娱乐棋牌官方版 889棋牌官方版 口袋棋牌2933 虎牙棋牌官网版 太阳棋牌旧版 291娱乐棋牌官网版 济南震东棋牌最新版 盛世棋牌娱乐棋牌 虎牙棋牌手机版 889棋牌4.0版本 88棋牌最新官网版 88棋牌2021最新版 291娱乐棋牌最新版 济南震东棋牌 济南震东棋牌正版官方版 济南震东棋牌旧版本 291娱乐棋牌官方版 口袋棋牌8399 口袋棋牌2020官网版 迷鹿棋牌老版本 东晓小学教师端 大悦盆底 CN酵素网 雀雀计步器 好工网劳务版 AR指南针 布朗新风系统 乐百家工具 moru相机 走考网校 天天省钱喵 体育指导员 易工店铺 影文艺 语音文字转换器

