欢迎来到noYes游戏王国
网站导航
在上一篇文章中,小编为您详细介绍了关于《美国空军选择雷神技术公司开发远程防区外巡航导弹》相关知识。本篇中小编将再为您讲解标题百度11篇论文被国际自然语言处理顶级会议ACL2020录用。
原标题:百度11篇论文被国际自然语言处理顶级会议ACL 2020录用
近日,国际自然语言处理领域顶级学术会议“国际计算语言学协会年会”(ACL 2020)公布了今年大会的论文录用结果。根据此前官方公布的数据,本届大会共收到3429篇投稿论文,投稿数量创下新高。其中,百度共有11篇论文被大会收录,再次展现出在自然语言处理领域的超高水准。
国际计算语言学协会(ACL,The Association for Computational Linguistics)是自然语言处理领域影响力最大、最具活力的国际学术组织之一,百度 CTO 王海峰曾任2013年 ACL 主席(President),是 ACL 历史上首位华人主席。
除了在国际 AI 学界的影响力外,ACL 无论是审稿规范还是审稿质量,都是当今 AI 领域国际顶级会议中公认的翘楚。研究论文能够被其录用,不仅意味着研究成果得到了国际学术界的认可,也证明了研究本身在实验严谨性、思路创新性等方面的实力。而此次 ACL 2020的审稿周期,从去年12月一直持续到今年4月,相比往年几乎增加了一倍。虽然大会官方尚未公布今年整体论文录用率,但参照往年的评审过程和录用率,论文被其录取的难度依旧不会低。
百度的自然语言处理技术,在发展及应用上始终保持领先,一直被视为自然语言处理研究界的“第一梯队”。今年除了11篇论文被录用外,大会期间百度还将联合 Google、Facebook、UPenn、清华大学等海内外顶尖企业及高校,共同举办首届同声传译研讨会(The 1st Workshop on Automatic Simultaneous Translation)。由于近期疫情影响,原定于今年7月5日至10日在美国西雅图举行的大会已改为线上举办,而上述同声传译研讨会也将改为在线上与专家学者们探讨。
本届大会百度被收录的11篇论文,覆盖了对话与交互系统、情感分析/预训练表示学习、NLP 文本生成与摘要、机器翻译/同声翻译、知识推理、AI 辅助临床诊断等诸多自然语言处理界的前沿研究方向,提出了包括情感知识增强的语言模型预训练方法、基于图表示的多文档生成式摘要方法 GraphSum 等诸多新算法、新模型、新方法,不仅极大提升了相关领域的研究水平,也将推动人机交互、机器翻译、智慧医疗等场景的技术落地应用。
以下为 ACL 2020百度被收录的11篇论文概览。
一、对话与交互系统
1、Conversational Graph Grounded Policy Learning for Open-Domain Conversation Generation
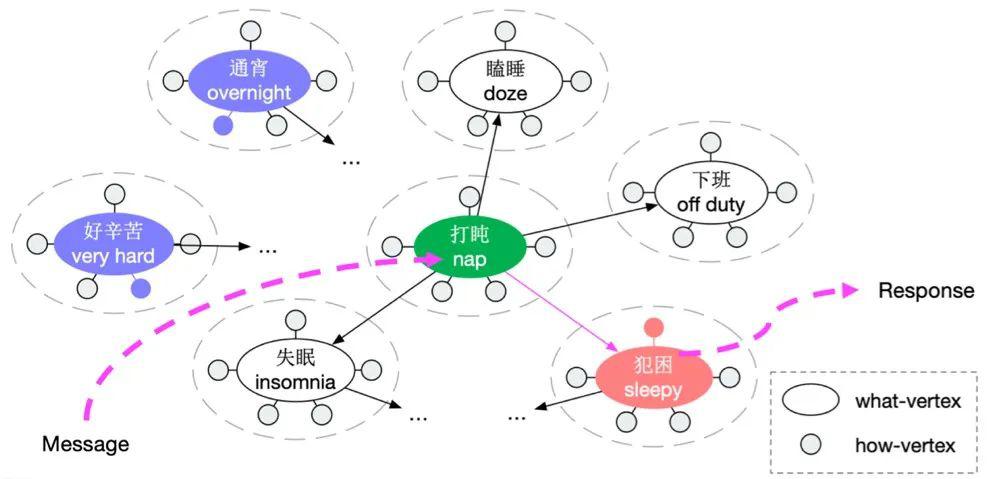
我们提出用图的形式捕捉对话转移规律作为先验信息,用于辅助开放域多轮对话策略学习。
我们可以有效地利用CG来促进对话策略学习,具体而言:
(1)可以基于它设计更有效的长期奖励;
(2)它提供高质量的候选操作;
(3)它让我们对策略有更多的控制。
我们在两个基准语料库上进行了实验,结果证明了本文所提框架的有效性。
2、PLATO: Pre-trained Dialogue GenerationModel with Discrete Latent Variable
研发开放领域(Open-Domain)的对话机器人,使得它能用自然语言与人自由地交流,一直是自然语言处理领域的终极目标之一。
对话系统的挑战非常多,其中有两点非常重要,一是大规模开放域多轮对话数据匮乏;二是对话中涉及常识、领域知识和上下文,一个对话的上文(Context),往往可以对应多个不同回复(Response)的方向。PLATO 首次提出将离散的隐变量结合Transformer结构,应用到通用对话领域。通过引入离散隐变量,可以对上文与回复之间的“一对多”关系进行有效建模。
同时,通过利用大规模的与人人对话类似的语料,包括 Reddit 和 Twitter,进行了生成模型的预训练,后续在有限的人人对话语料上进行微调,即可以取得高质量的生成效果。PLATO 可以灵活支持多种对话,包括闲聊、知识聊天、对话问答等等。而文章最终公布的在三个公开对话数据集上的评测,PLATO 都取得了新的最优效果。
尽管越来越多的工作证明了随着预训练和大规模语料的引入,自然语言处理领域开启了预训练然后微调的范式。在对话模型上,大规模预训练还处于初级阶段,需要继续深入探索。PLATO 提出的隐变量空间预训练模型,可能成为端到端对话系统迈上一个新台阶的关键点之一。
3、Towards Conversational Recommendation over Multi-Type Dialogs
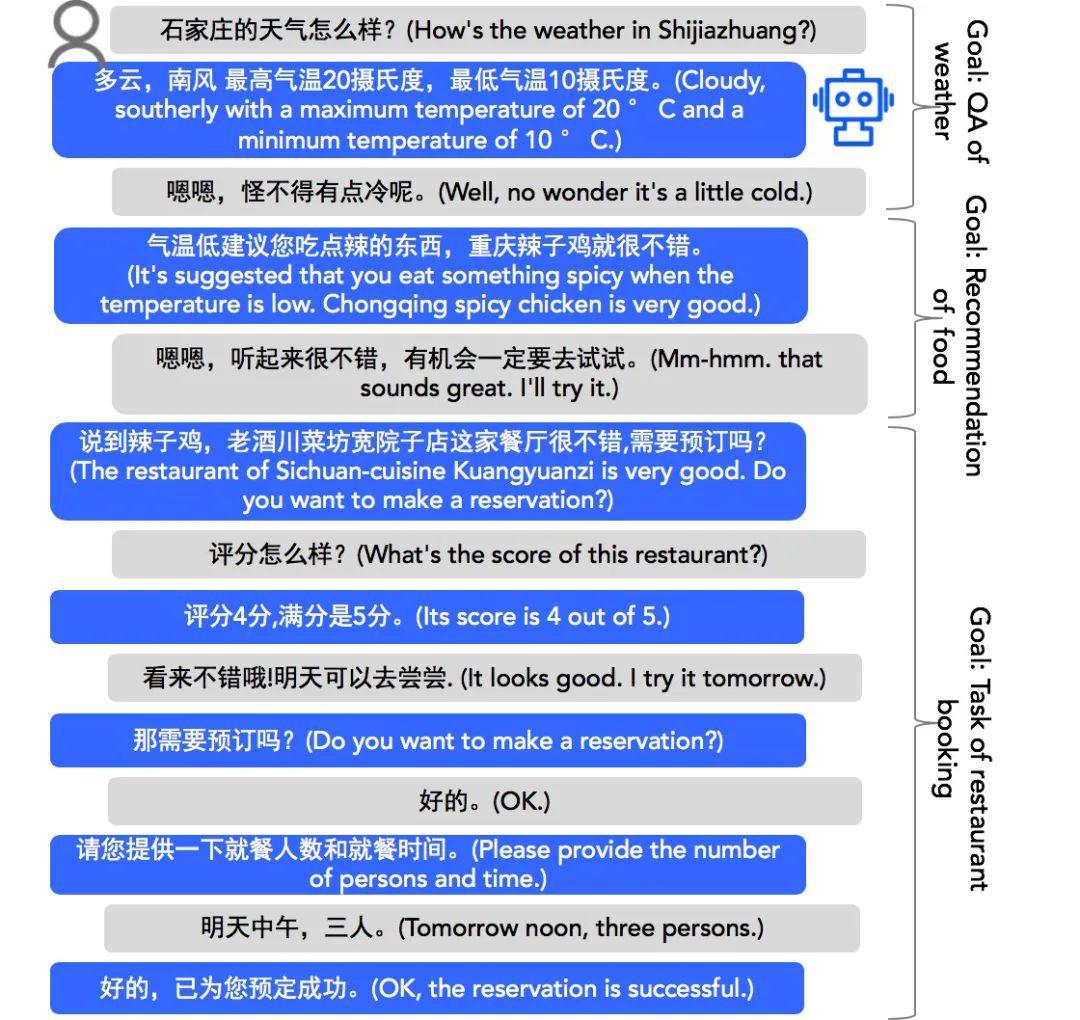
真实人机对话,涉及多类型对话(闲聊、任务型对话、问答等),如何自然的融合多类型对话是一个重要的挑战。
为应对这个挑战,我们提出一个新的任务——多类型对话中的对话式推荐,期望 Bot 能够主动且自然地将对话从非推荐对话(比如『问答』)引导到推荐对话,然后基于收集到的用户兴趣及用户实时反馈通过多次交互完成最终的推荐目标。
为便于研究这个任务,我们标注了一个包含多种对话类型、多领域和丰富对话逻辑(考虑用户实时反馈)的人-人对话式推荐数据集 DuRec(1万个对话和16.4万个 utterance)。针对每个配对:推荐寻求者(user)和推荐者(bot),存在多个序列对话,在每个对话中,推荐者使用丰富的交互行为主动引导一个多类型对话不断接近推荐目标。
这个数据集允许我们系统地考察整个问题的不同部分,例如,如何自然地引导对话,如何与用户交互以便于推荐。最后,我们使用一个具有多对话目标驱动策略机制的对话生成框架在 DuRec 上建立基线结果,表明了该数据集的可用性,并为将来的研究设定了基线。
二、情感分析/预训练表示学习
4、SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis
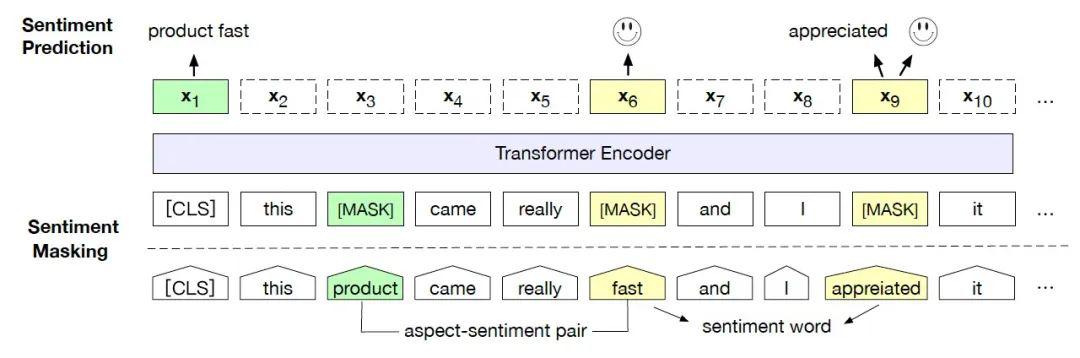
近年来,随着预训练语言模型的快速发展,情感分析等多项自然语言理解任务都取得了显著的效果提升。然而,在通用语言模型预训练中,文本中的很多情感相关的知识和信息,例如情感词、实体-评论搭配等,并没有被模型充分的学习。
基于此,百度提出了一种情感知识增强的语言模型预训练方法,在通用预训练的基础上,设计了面向情感知识建模的 Masking 策略和情感多目标学习算法,融合了情感词、极性、主体评论关系等多层情感知识,首次实现了情感任务统一的文本预训练表示学习。
该算法在情感分类、观点抽取等情感分析任务中相对主流预训练模型RoBERTa有显著的提升,同时刷新了多个情感分析标准测试集的世界最好水平。
5、Cross-Lingual Unsupervised Sentiment Classification with Multi-View Transfer Learning
本文针对无标签资源的目标语言,提出了一种无监督的跨语言情感分析模型。
三、NLP 文本生成与摘要
6、Leveraging Graph to Improve Abstractive Multi-Document Summarization

多文档摘要(Multi-Document Summarization)技术自动为主题相关的文档集生成简洁、连贯的摘要文本,具有广阔的应用场景,例如热点话题综述、搜索结果摘要、聚合写作等。
生成式多文档摘要方法的难点之一是如何有效建模文档内及文档间的语义关系,从而更好地理解输入的多文档。为此,本论文提出基于图表示的多文档生成式摘要方法 GraphSum,在神经网络模型中融合多文档语义关系图例如语义相似图、篇章结构图等,建模多篇章输入及摘要内容组织过程,从而显著提升多文档摘要效果。
GraphSum 基于端到端编解码框架,其中图编码器利用语义关系图对文档集进行编码表示,图解码器进一步利用图结构组织摘要内容并解码生成连贯的摘要文本。GraphSum 还可以非常容易地与各种通用预训练模型相结合,从而进一步提升摘要效果。在大规模多文档摘要数据集 WikiSum 和 MultiNews 上的实验表明,GraphSum 模型相对于已有的生成式摘要方法具有较大的优越性,在自动评价和人工评价两种方式下的结果均有显著提升。
7、Exploring Contextual Word-level Style Relevance for Unsupervised Style Transfer
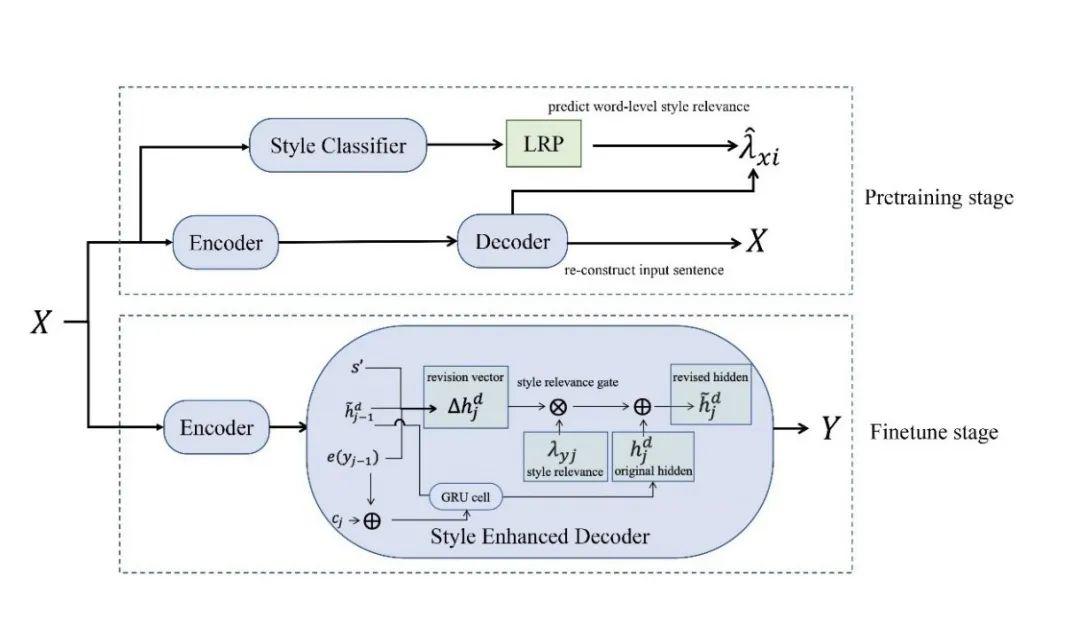
无监督风格转换是指在无平行语料的情况下,把输入的句子改成目标风格,同时尽可能保持其原义。
本文提出了一种全新的序列到序列的生成模型,可以动态地根据生成词的风格相关性进行风格转换。本文有两个主要的创新点:
实验表明,本文提出的方法在情感风格转换和口语化风格转换的任务上都达到了领先效果。
四、机器翻译&同声翻译
8、Opportunistic Decoding with Timely Correction for Simultaneous Translation

同声传译有许多重要的应用场景,近年来受到学术界和业界的广泛关注。然而,大多数现有的框架在翻译质量和延迟之间难以平衡,即解码策略通常要么过于激进,要么过于保守。
在本论文中,百度首次提出了一种具有及时纠错能力的解码技术,它总是在每一步产生一定数量的额外单词,以保持观众对最新信息的跟踪,同时,它也在观察更多的上下文时,对前一个过度生成的单词提供及时的纠错,以确保高翻译质量。
本文还首次提出了对这种纠错场景下的延迟指标。实验表明,我们的技术提高了延迟和质量:延迟减少了2.4,BLEU 增加了3.1,中英翻译和中英翻译的修改率低于8%。本系统可用于任何语音到文本的同传系统中。
9、Simultaneous Translation Policies: fromFixed to Adaptive
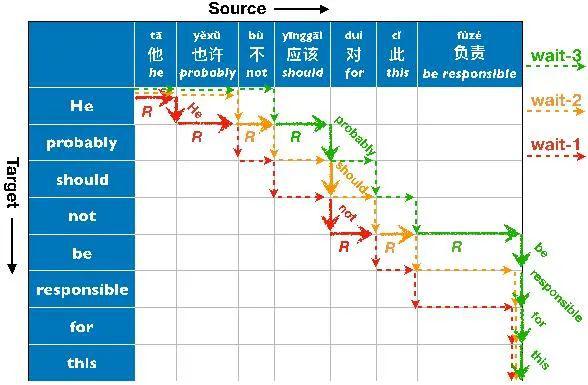
同声翻译是机器翻译中的一个重要问题,它不仅要求高质量的翻译结果,而且要求翻译的过程有较低的时延。同声翻译的过程可以认为是一个选择“读”或“写”的决策过程,而所采用的策略则决定了同声翻译的质量与时延。
本文提出一种简单的启发式算法,根据翻译模型输出的概率分布,可以将几种精简的固定“读写”策略组合成一种灵活的策略。本文进一步将该算法与集成方法相结合,既提高了翻译质量,又降低了翻译过程的时延。这种简单的算法不需要训练策略模型,使得其更易于在产品中使用。
五、知识推理
10、Learning Interpretable Relationships between Entities, Relations and Concepts via Bayesian Structure Learning on Open Domain Facts
通过贝叶斯结构学习建立了开放领域的关系与概念(Concept)之间的关联,使得实体为何属于某个概念的原因得到了很好的解释。
六、AI 辅助临床诊断
11、Towards Interpretable Clinical Diagnosiswith Bayesian Network Ensembles Stacked on Entity-Aware CNNs
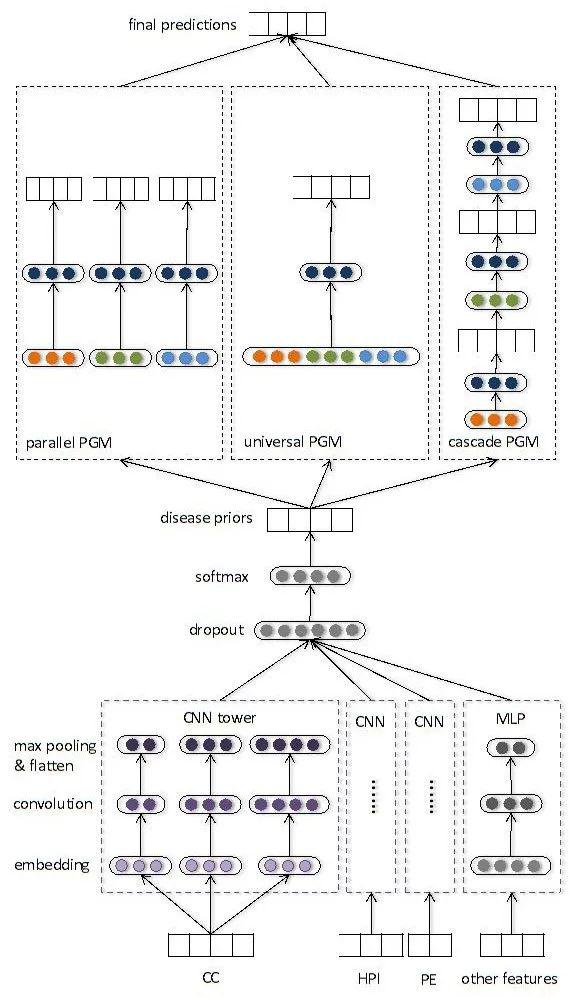
基于电子病历(EMR)的智能化诊断算法是 AI 医疗研究领域最重要、最活跃、应用最广泛的问题之一。
传统的诊断算法或者直接使用端到端分类模型,丢失了可解释性,或者仅基于知识关系和规则进行推理,可迁移、可扩展性低。本研究提出一种新的诊断算法框架,该框架针对EMR具有无结构化文本和结构化信息并存的特点,结合医疗NLU,以深度学习模型实现EMR的向量化表示、诊断预分类和概率计算。
结合医疗知识图谱增强的多种贝叶斯网络的组合模型,实现具有可解释性的诊断推理。该框架能同时兼顾高诊断准确率和强可解释性的特点,并可应用于面向基层医师的辅助临床诊断产品中。游戏网
编后语:关于《百度11篇论文被国际自然语言处理顶级会议ACL2020录用》关于知识就介绍到这里,希望本站内容能让您有所收获,如有疑问可跟帖留言,值班小编第一时间回复。 下一篇内容是有关《工业富联:在新基建领域已具备较强“先发优势”》,感兴趣的同学可以点击进去看看。




























































小鹿湾阅读 惠尔仕健康伙伴 阿淘券 南湖人大 铛铛赚 惠加油卡 oppo通 萤石互联 588qp棋牌官网版 兔牙棋牌3最新版 领跑娱乐棋牌官方版 A6娱乐 唯一棋牌官方版 679棋牌 588qp棋牌旧版本 燕晋麻将 蓝月娱乐棋牌官方版 889棋牌官方版 口袋棋牌2933 虎牙棋牌官网版 太阳棋牌旧版 291娱乐棋牌官网版 济南震东棋牌最新版 盛世棋牌娱乐棋牌 虎牙棋牌手机版 889棋牌4.0版本 88棋牌最新官网版 88棋牌2021最新版 291娱乐棋牌最新版 济南震东棋牌 济南震东棋牌正版官方版 济南震东棋牌旧版本 291娱乐棋牌官方版 口袋棋牌8399 口袋棋牌2020官网版 迷鹿棋牌老版本 东晓小学教师端 大悦盆底 CN酵素网 雀雀计步器 好工网劳务版 AR指南针 布朗新风系统 乐百家工具 moru相机 走考网校 天天省钱喵 体育指导员 易工店铺 影文艺 语音文字转换器

