欢迎来到noYes游戏王国
网站导航
在上一篇文章中,小编为您详细介绍了关于《科大讯飞,可能是国内最(谐门)魔幻的科技企业》相关知识。本篇中小编将再为您讲解标题Sharding-Proxy核心原理与性能优化。
原标题:Sharding-Proxy核心原理与性能优化

作者介绍
张永伦,京东数科软件开发工程师,Apache ShardingSphere (Incubating) PPMC。2018年2月参与到ShardingSphere项目中,经历了在Apache孵化的整个过程。比较擅长Sharding-Proxy,SQL-Parser,APM和性能测试方向。
分享的内容分为四部分。首先,Sharding-Proxy简介:包括Proxy在ShardingSphere中的定位,Proxy架构和特性的介绍。第二部分,SQL的一生:在这里,我们从一个简单查询SQL的角度,了解Sharding-Proxy内部的运转流程。第三部分,核心原理:会介绍几个不难理解,但对Sharding-Proxy非常重要的原理。最后,性能优化:对于Sharding-Proxy这种应用,它的可用性和性能是非常重要的指标,所以在这里总结一下之前出现的比较有共性的问题。还会介绍一下目前是如何进行性能保障的。
1、Apache ShardingSphere生态圈
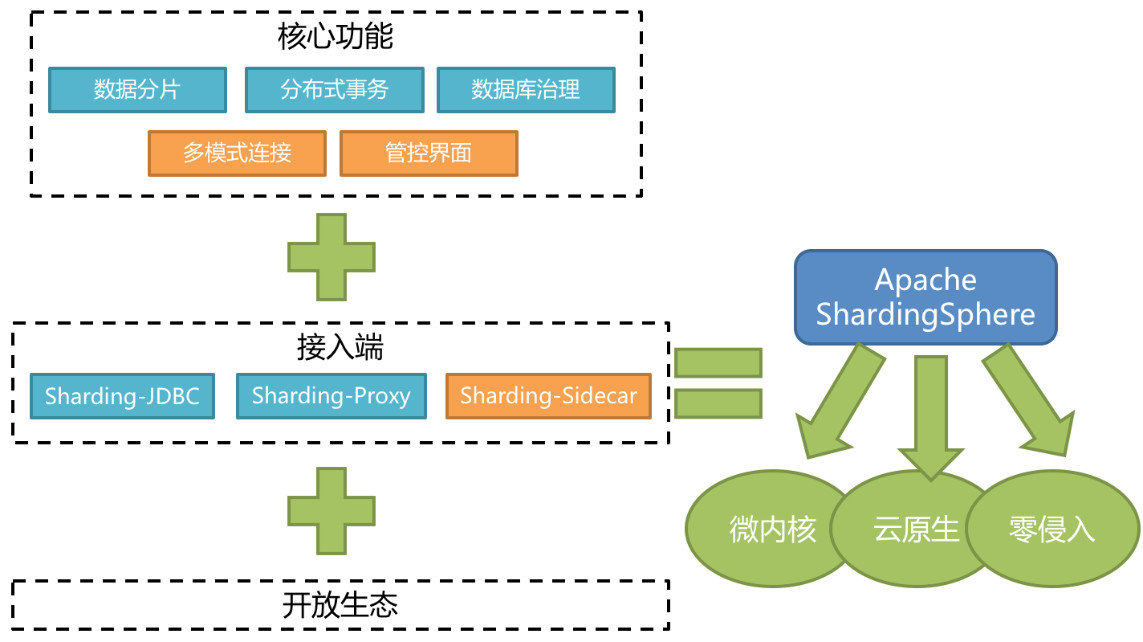
我们来看一下ShardingSphere的定位。它是一个分布式数据库中间件组成的生态圈,之所以说它是一个生态圈,是因为它整个功能的设计是一个闭环的结构,另外也会给用户提供多种接入方式,来方便用户在生产当中面对不同的接入需求。现在大家看到的是ShardingSphere的整体架构,它的功能由五大块组成。分别是数据分片,分布式事务,数据库治理,这三块已经上线交付用户使用。管控界面近期也由社区开发完成并捐献给Apache基金会。多模式连接还在规划和开发的进程中。底下是它的接入端,我们为大家提供了三款产品,分别是Sharding-JDBC,Sharding-Proxy和Sharding-Sidecar。每一款接入端都具备上面所有的功能,三款产品分别满足用户不同生产场景的需求。
2、Sharding-Proxy架构
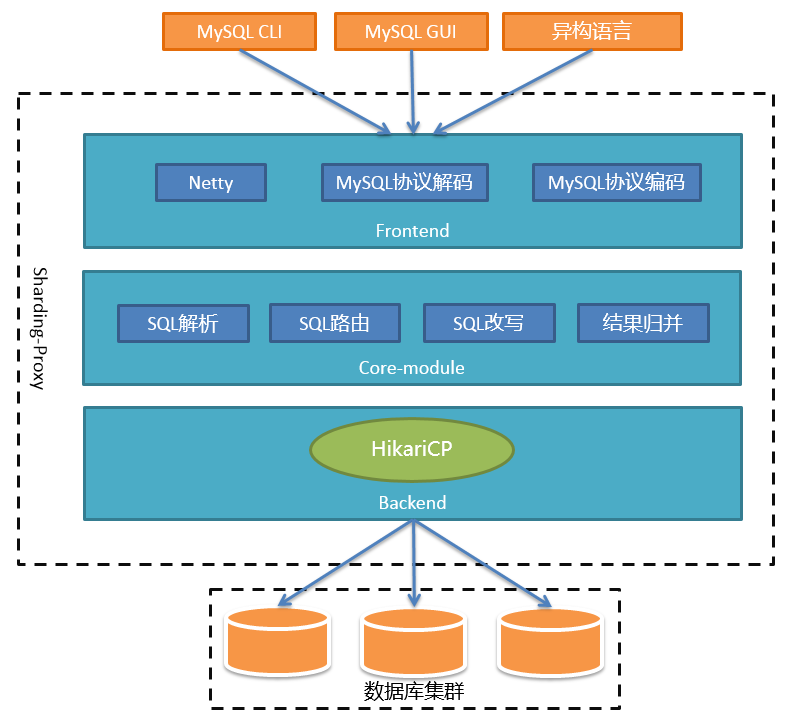
下面进入正题。Sharding-Proxy的定位是透明化的数据库代理,它封装了数据库二进制协议,用于完成对异构语言的支持。目前兼容MySQL和PG,可以使用任何兼容MySQL或PG协议的客户端进行访问,比如MySQL命令行、MySQL Workbench、Navicat等等,对DBA更加友好。
整个架构可以分为前端、后端和核心组件三部分。前端负责与客户端进行网络通信,采用的是基于NIO的客户端/服务器框架,在Windows和Mac操作系统下采用NIO 模型,Linux系统自动适配为Epoll模型。通信的过程中完成对MySQL协议的编解码。核心组件得到解码的MySQL命令后,开始调用Sharding-Core对SQL进行解析、路由、改写、结果归并等核心功能。后端与真实数据库的交互目前借助于Hikari连接池。
1、业务场景
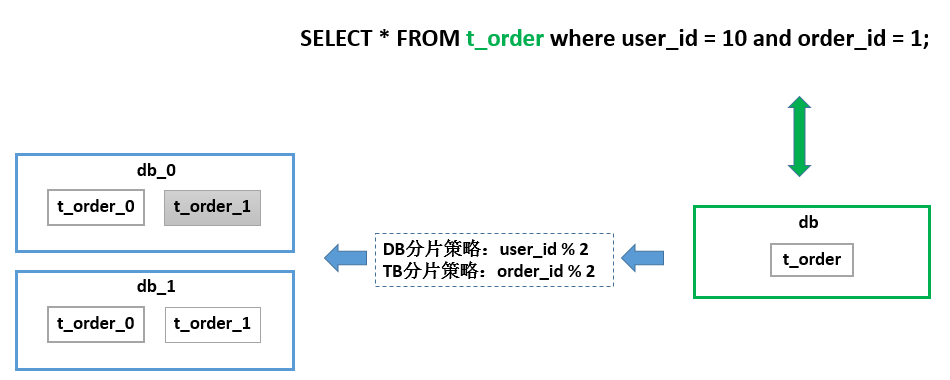
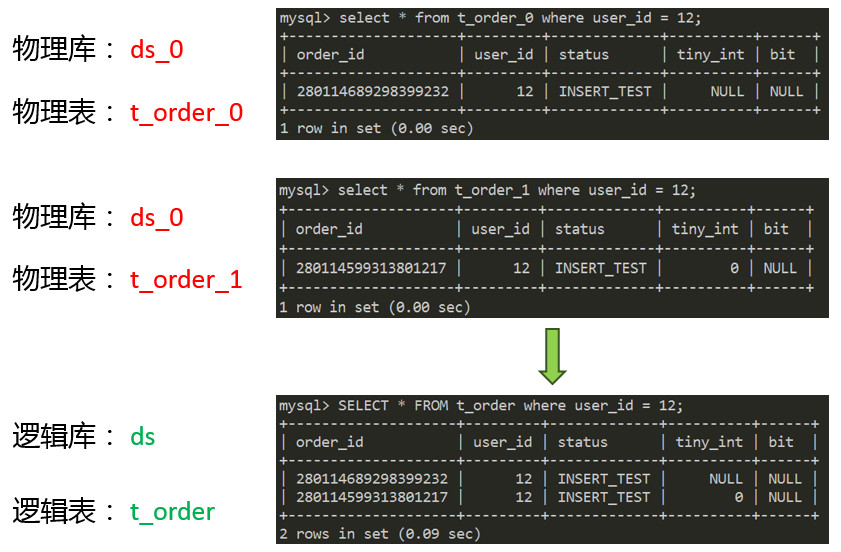
大家可以看到,整个ShardingSphere的功能还是非常多的,短时间内肯定无法一一讲到。那么我们就从数据分片,这样一个比较核心,比较基础,又非常重要的功能点来展开跟大家分享。数据分片我觉得大家多少都会有所了解,基本原理就是把一个库拆分成多个库,把一个表拆分成多个表。来达到水平扩展的目的。在这个场景里有一个数据库,里面只有一张表,叫t_order。由于它的数据量很大,所以它在底层存储的时候已经进行了拆分。按照这样的分片策略拆分成了两个库,每个库两张表。Sharding-Proxy帮助用户屏蔽掉了真实的库表,用户的SQL只需针对逻辑库表就可以了。
2、MySQL协议解码
SELECT * FROM t_order where user_id = 10 and order_id = 1;
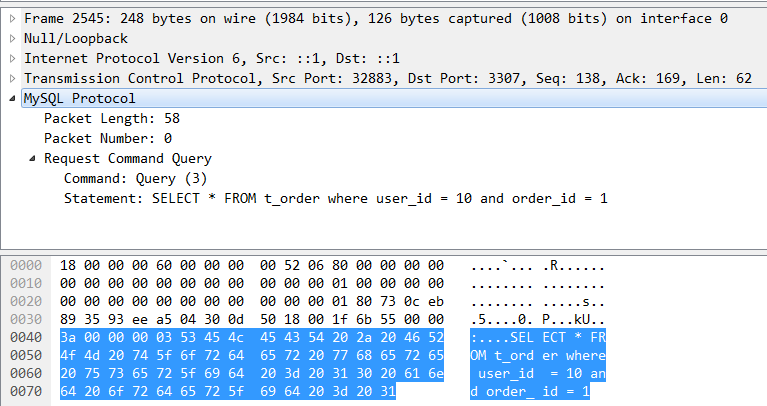
我们现在看一下这个SQL是怎么来的,它的真实面目是什么。当连接Proxy的客户端执行一个SQL的时候,我们可以通过Wireshark在网络上抓到这个包。可以看到,MySQL协议是承载在TCP协议之上的。传输方向是32883端口到3307端口,这个3307是 Proxy的默认端口。MySQL协议也像大多数协议一样遵循TLV原则:
Proxy解码出逻辑SQL后,就会立即把它送给解析模块处理。
3、SQL解析
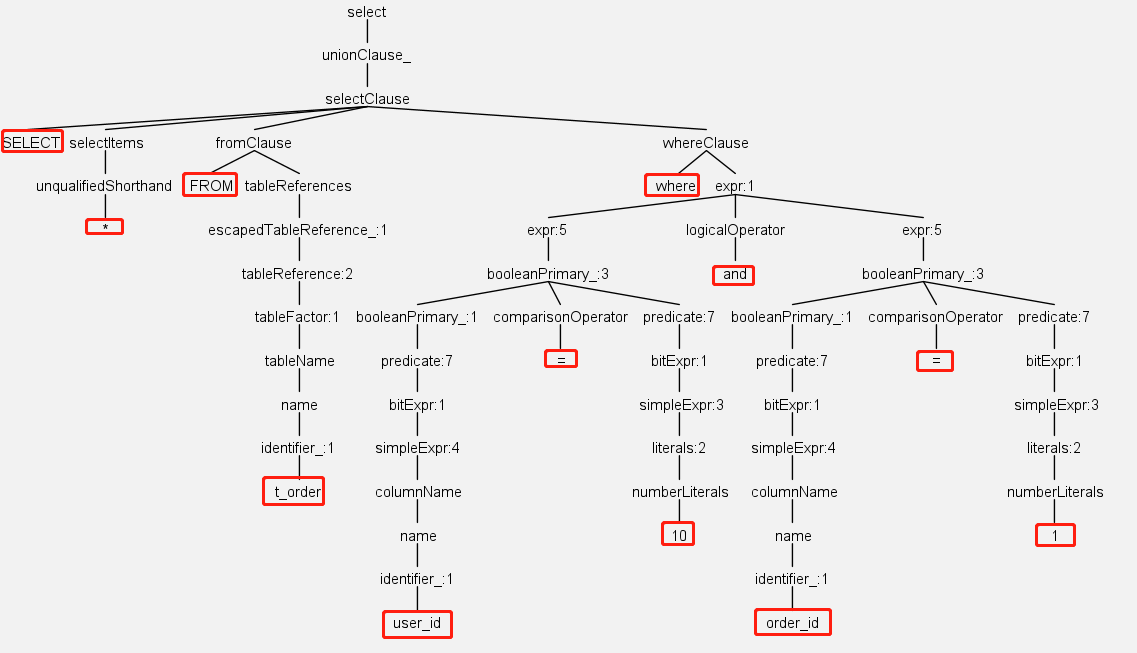
我们现在看到的是SQL经过解析后生成的抽象语法树。这个语法树是由Antlr自动生成的。
解析过程分为词法解析和语法解析。词法解析器用于将SQL拆解为不可再分的原子符号(比如select, from, t_order, 还有*, =,10),之后语法解析器将SQL转换为抽象语法树。有了这个语法树之后,通过对其遍历,就可以提炼出分片所需的上下文,并标记有可能需要改写的位置。比如user_id和order_id的值要取出来,他们是分片键,决定路由的结果。表t_order的位置要记录下来,改写的时候才能找到。
4、路由
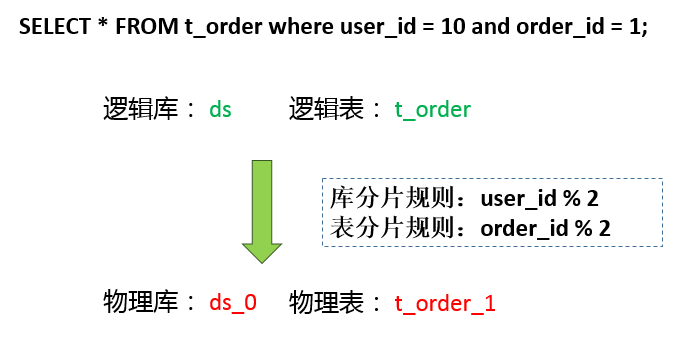
在当前的这个简单分片规则下,真实库的计算方式是 user_id % 2 => 10 % 2,路由到ds_0库。同理,真实表order_id % 2 => 1 % 2,路由到t_order_1。当然,路由的功能不止这么简单。路由引擎支持多种分片策略,包括取模、哈希、范围、标签、时间等等。还支持多种分片接口,包括行表达式、内置规则、自定义类等方式。
5、改写
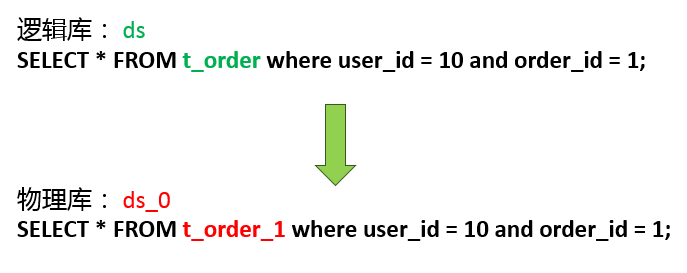
为什么要改写?上面这个面向逻辑库与逻辑表的SQL,并不能够直接在真实的数据库中执行,SQL改写的作用就是把逻辑SQL改写为可以在真实库中正确执行的真实SQL。真实库和真实表我们之前已经知道了,所以直接把SQL改写为这样。并不是所有SQL的改写都这么简单,比如聚合函数怎么改写,包含LIMIT的SQL怎么改写,什么时候需要补列,这些都是改写引擎需要处理的事情。
6、执行
路由改写完成了,就可以从连接池里取连接执行SQL了。整个执行过程是通过ShardingSphere的执行引擎完成的。执行引擎会根据路由节点的数量和单次查询单库允许的最大连接数,自动决策出是否使用流式结果集。流式结果集会最大程度减少内存的压力。这个真实SQL最后被Proxy发送到MySQL服务器。在MySQL服务器里经过一系列的缓存、解析、优化后,从存储引擎里把结果数据取出来并返回给Proxy。
7、归并
Proxy收到结果数据后,需要对数据进行归并处理。为了方便说明归并,我们换一个SQL。这个SQL只包含一个分片键user_id,那么它会被路由到ds_0库。由于没有指定order_id,所以会被路由到全部的真实表t_order_0和t_order_1。两个真实表分别存在一条满足条件的数据,那么归并就是将这两条数据合并起来返回给客户端。归并引擎的功能很强大,我们这个例子属于最简单的遍历归并。还有很多其他的归并场景:比如,排序归并:SQL中存在order by时,需要考虑如何排序代价最小。再比如,分组归并:在SQL中同时存在order by和group by的情况下,需要考虑如何优化内存占用率。
8、MySQL协议编码
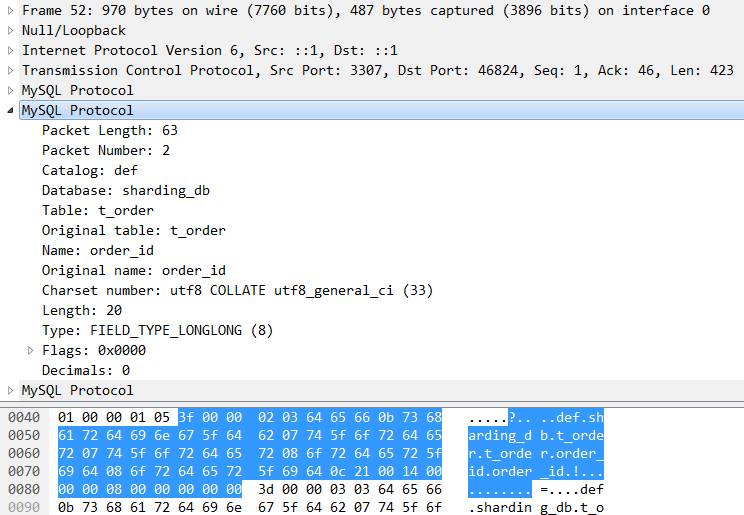
得到了最终的归并结果后,Proxy会把这个结果编码成MySQL协议发送给客户端。数据包中包含每一列的描述信息,比如数据库名、表名、字符集、数据类型等等。
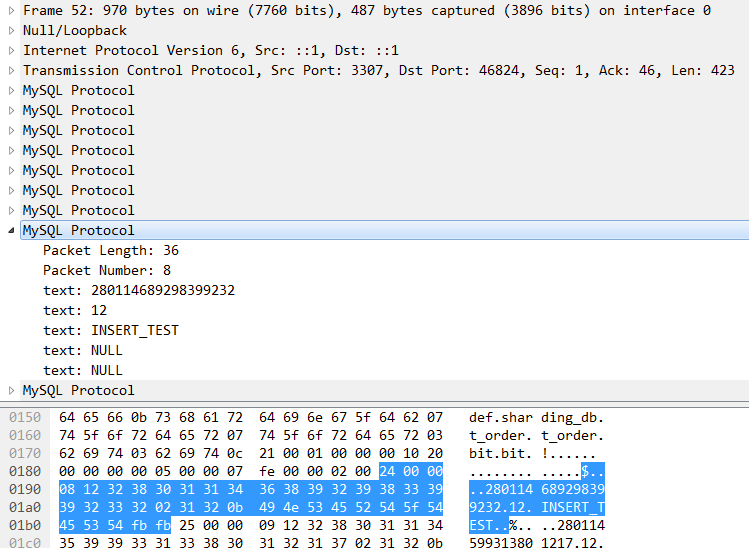
还有就是用户可见的结果数据。MySQL命令行客户端收到协议包后,会在终端上打印结果数据。如果使用的是JDBC客户端,JDBC会把所有结果保存到ResultSet里面。以上就是Sharding-Proxy的一个简要流程。
1、IO & 线程模型
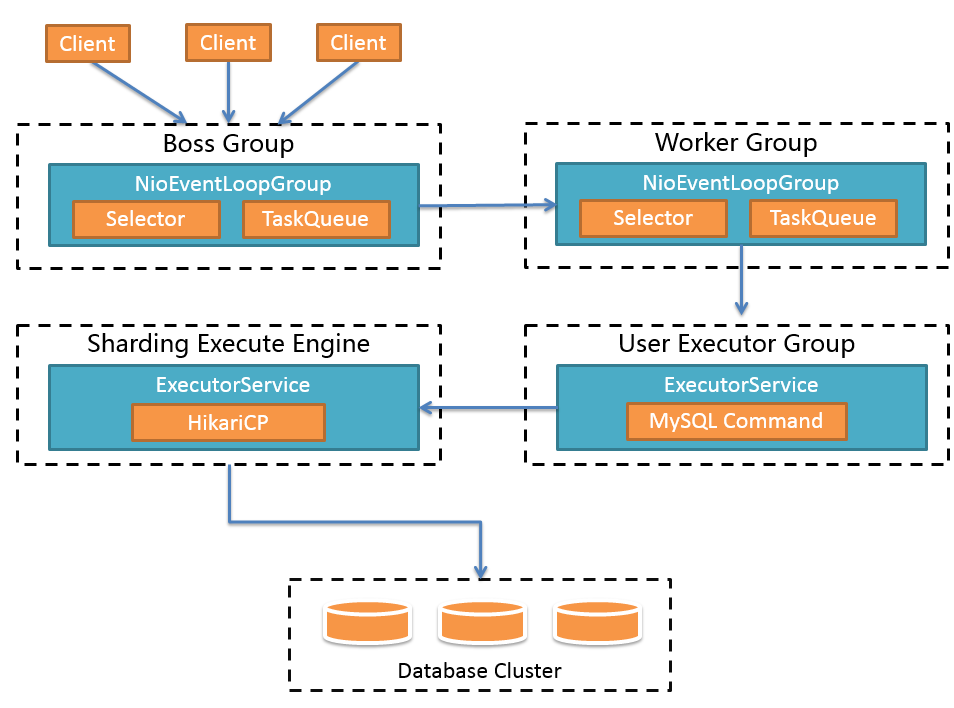
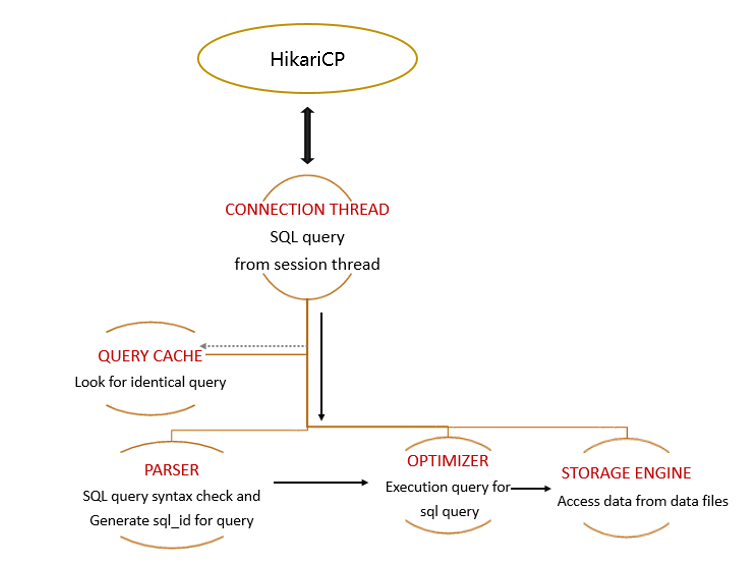
核心原理部分首先介绍一下IO模型和线程模型。可以简单理解上面两个是前端,下面两个是后端。Boss Group相当于Reactor模式中的Reactor。Worker Group相当于模式中的Worker。User Executor Group用于执行MySQL命令。Sharding Execute Engine用于并发访问数据库。大家看到Boss Group和Worker Group应该能猜到前端用的是Netty。所以前端使用IO多路复用处理客户端请求。后端使用的是Hikari连接池,同步请求数据库。如果开启XA事务,情况就会比较特殊。由于Atomiks事务管理器的资源是threadlocal的,所以一次事务的所有SQL必须全部在同一个线程中执行。在执行MySQL命令的时候会单独创建一个线程,并缓存起来。
2、流式归并

下面介绍两个早期开发时遇到的问题,实现起来不难,但是原理值得研究一下。这是我在自己电脑上测试的一个场景,使用5个JDBC客户端连接Proxy,每个客户端查询出15万条数据。可以看到,Proxy的内存在一直增长,即使GC也回收不掉。这是因为在收到全部15万条数据之前,JDBC ResultSet的get()方法是阻塞的。简单说,就是JDBC在没收到全量结果之前,是不让用户读数据的,这是ResultSet的默认提取数据方式。会导致Proxy缓存大量临时数据。那么,有没有一种办法,能让ResultSet一收到结果就立即给用户消费呢?
从Connector/J文档上可以找到两种解决方法:

一种是流式结果集:只要把Statement的FetchSize设置成这个值,JDBC就会使用流式ResultSet处理返回结果,让用户能够一边接收数据一边消费数据,而不需要全部接收完再消费。

另一种方式是基于游标的流式结果集:设置JDBC参数useCursorFetch=true,表示要使用游标。设置FetchSize,指示每次返回数据的行数。
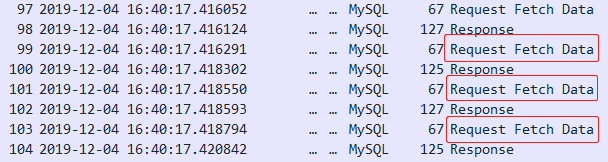
这种方式效率很低,要谨慎使用。通过抓包可以发现,客户端每次读取数据都会向服务端发送Request Fetch Data这个请求,在网络上的时间开销是非常大的。

Proxy采用的是第一种方案,可以看到内存已经恢复正常了。流式结果集是流式归并的前提条件,流式归并还要满足SQL条件和连接数条件,比较复杂,这里就不详细介绍了。这个内存使用效果是在最理想的情况下产生的,也就是客户端从Proxy消费数据的速度,大于等于Proxy从MySQL消费数据的速度。
3、限流
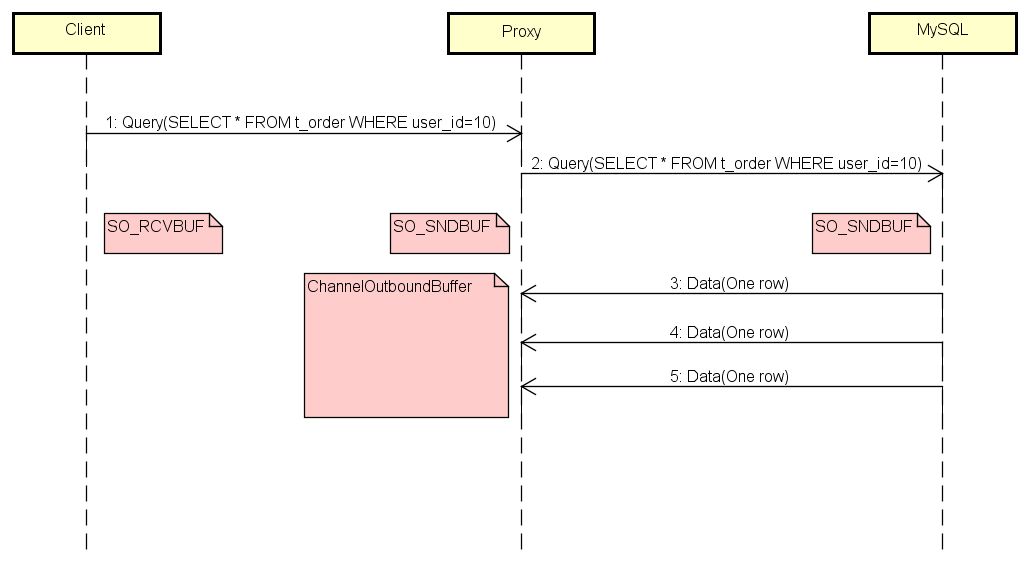
如果客户端由于某种原因消费变慢了,或者干脆不消费了,会发生什么呢?通过测试发现,内存使用量直线飙升,比刚才那张图还夸张。我们来研究下为什么会产生这种现象。这里加上了几个主要的缓存,SO_RCVBUF和SO_SNDBUF,他们是TCP的缓存。
ChannelOutboundBuffer是Netty写缓存。在结果数据回传的过程中,如果Client阻塞,那么他的SO_RCVBUF会瞬间被数据填满,触发TCP的滑动窗口去通知Proxy不要再发送数据了。与此同时,数据就会积压到Proxy端,所以Proxy端的SO_SNDBUF也同时被填满了。Proxy的SO_SNDBUF满了之后,Netty的ChannelOutboundBuffer就会像一个无底洞一样,吞掉所有MySQL发来的数据,因为在默认情况下ChannelOutboundBuffer是无界的。由于Netty在消费,所以Proxy的SO_RCVBUF一直是空的,导致MySQL可以一直把数据发送过来,而Netty则不停的把数据存到ChannelOutboundBuffer,直到内存耗尽。
找到根本原因之后,我们需要做的就是当Client阻塞的时候,不让Proxy再接收MySQL的数据。Netty通过水位参数来控制写缓冲区,当buffer大小超过高水位线,我们就控制Netty不再往里面写,当buffer大小低于低水位线的时候,才允许写入。设置完水位线后,当ChannelOutboundBuffer满时,Proxy的SO_RCVBUF自然也满了,触发TCP滑动窗口通知MySQL停止发送数据。在这种情况下,Proxy所消耗的内存只是ChannelOutboundBuffer高水位线的大小。我们的目的就达到了。
4、分布式链路追踪系统
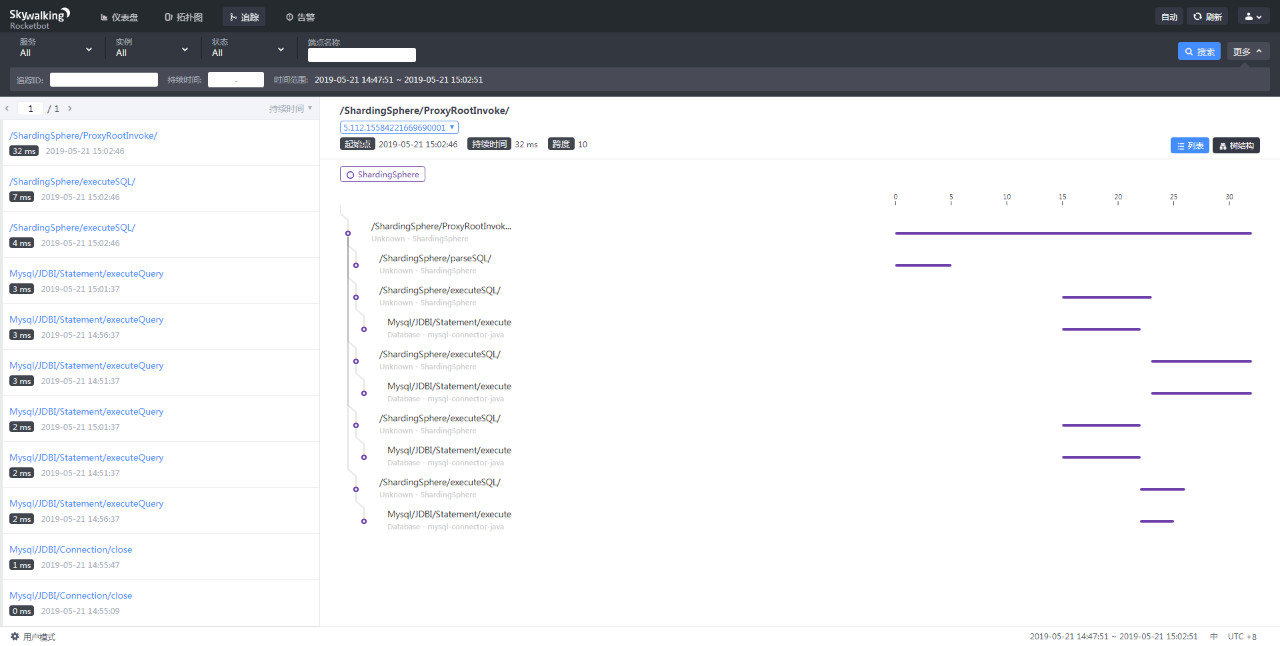
这个非常炫酷的界面来自Skywalking。他监控到了Sharding-Proxy中,执行一条SQL的完整调用链,而且对Proxy的代码没有任何侵入。他是怎么做到的呢?说道对代码没有侵入,大家首先想到的可能就是钩子。没错Skywalking就是使用的Instrument Agent实现的自动探针。目前已经支持的探针达几十种,涵盖了很多主流应用。如果把SkyWalking部署在一个真正的业务系统上,你看到的调用链会更加丰富。核心原理部分就介绍到这里。
1、代码
我在这里总结了一下常见的性能问题,有想提交代码的同学可以重点留意一下,避免出现相同的问题。
第一类是代码类问题。第一个例子:

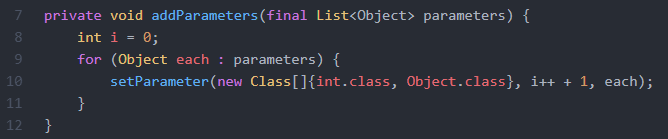
大家看一下这个函数,有什么问题吗?入参如果是LinkedList,可能会产生什么后果?LinkedList是链表,如果用下标get,时间复杂度是O(n)。循环n次,整个时间复杂度是O(n方)。换成for each遍历遍历就可以了。
这个之前有社区的同学测试过,50000个元素,执行时间相差1000多倍。
第二个例子:

如果把Properties当做整个系统的全局变量来使用,系统中大量并发调用getProperty()。Properties是Hashtable的子类,Hashtable的读写都是同步的。所以并发读会被串行处理。使用其他数据保存全局变量,比如ConcurrentHashMap。
2、额外非预期SQL
第二类是额外非预期SQL。第一个例子:

最近有一个PR,在每次执行SQL的时候调用了JDBC 的这个接口提取用户名。JDBC会利用select user()这个SQL,到数据库去查询用户名。导致在不知情的情况下,你认为执行了一个SQL,实际上执行了两个。优化方式就是把UserName缓存。性能可以提升32%。
第二个例子:
另外一个非预期SQL问题与我们之前使用的流式ResultSet有关。

这是我从JDBC 5.1.0的Release Notes上截的图。每创建一个流式ResultSet,JDBC都会设置一次网络超时时间。导致网络上有大量的 SET net_write_timeout 请求。
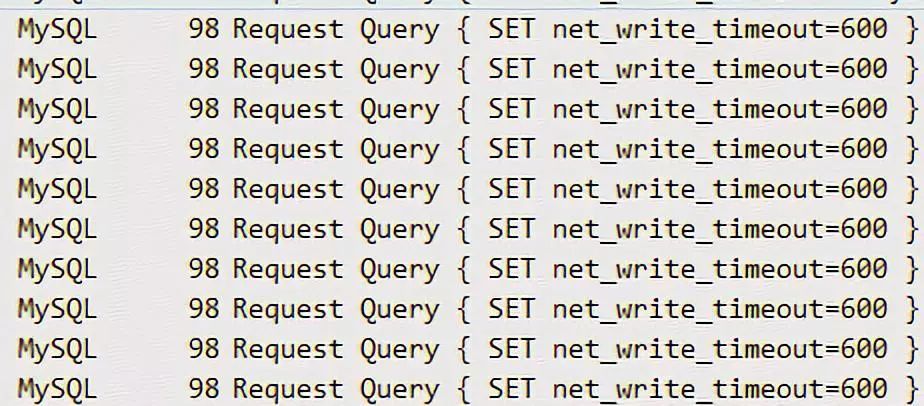
解决方式是手动把这个参数的值设为0。经过测试,性能提升33%。可见额外SQL对性能影响非常大,大家一定要注意。
3、IO & 系统调用
第三类涉及到比较底层的IO和系统调用。

Netty中发送数据分为两步:write()和flush()。Write()把数据写入netty的缓存中,flush()把数据发送出去。之前的实现是,每次从MySQL收到一条结果数据,就立刻flush一次把它发送到客户端。这样的用法效率很低。诺曼在《Netty In Action》里提到要尽量减少flush()的调用次数,因为系统调用的代价非常高。
其实不止系统调用代价高,网络利用率也很低。我们可以算一下,TCP每次发送数据,各种包头加起来要54字节(MAC头:14字节 + IP头:20字节 + TCP头:20字节),可能比你真正传输的数据都多。频繁的flush,单位时间内传输的有效数据肯定会变小。优化方式是多条结果调用一次flush(),性能提升达到50%。
4、全路由
最后一类是全路由问题。(这张图是京东数科内部的链路监控工具SGM,是对接京东白条现场的截图)
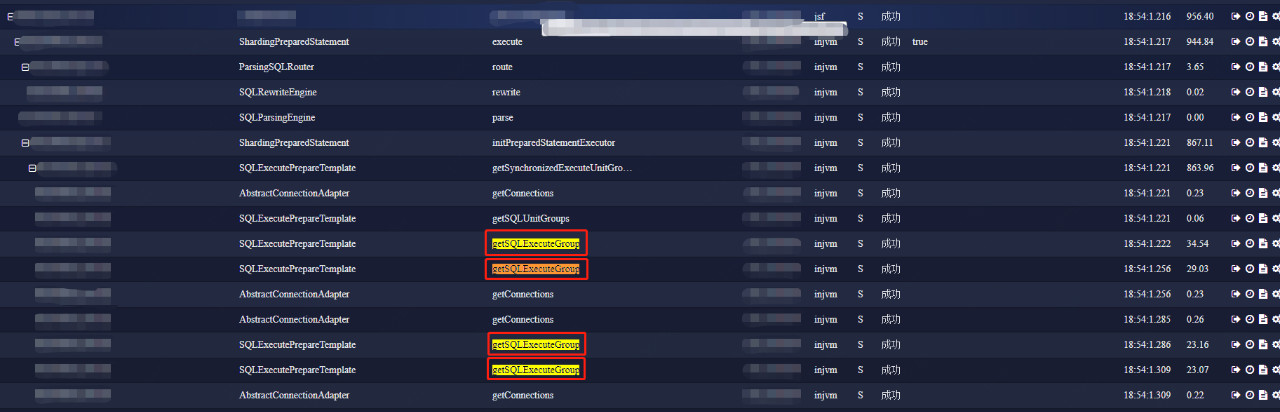
本来预期路由到单个节点的SQL,被路由到了n个节点。一般是由解析问题引起的。导致响应时间指数级增长。定位这类问题可以使用Java性能监控工具定位,例如JMC、JProfiler。或者APM工具SkyWalking、SGM等等。利用他们跟踪路由相关的函数,检查调用次数是否正确。
5、测试
为了能够即时发现性能问题,我们会对每个合并的PR进行性能测试,把问题定位在最小的范围内。
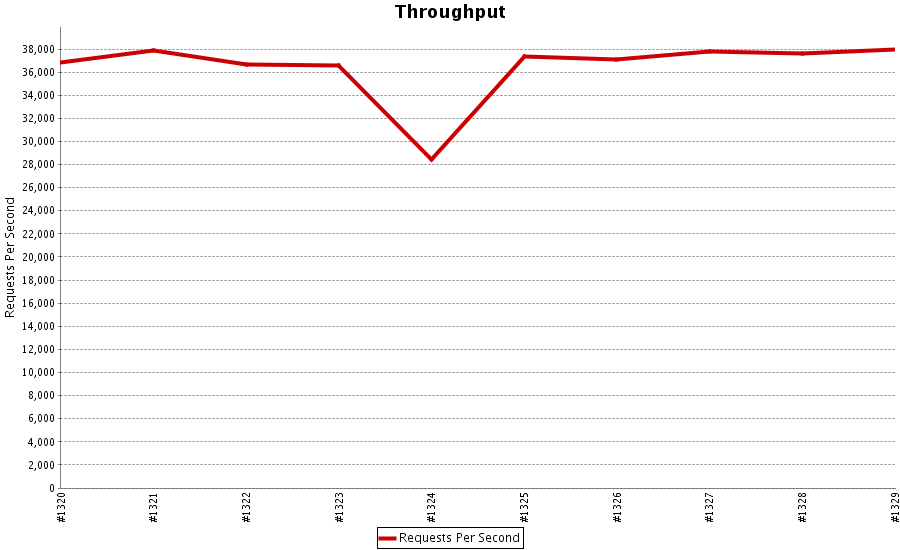
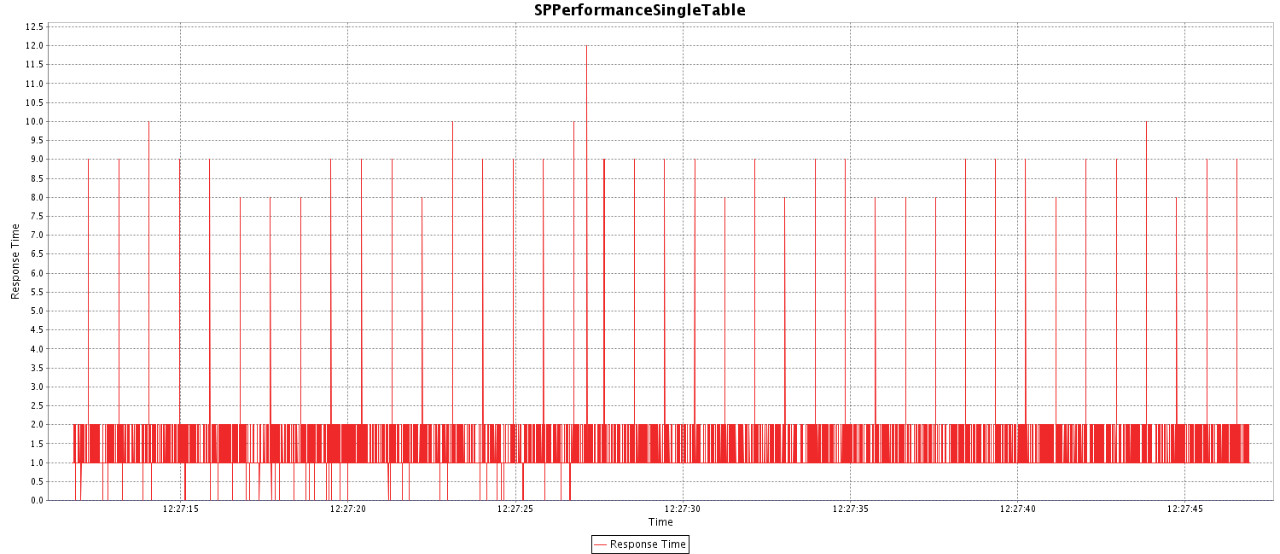
比如这次构建,性能明显下降,通过构建序号就能找到Github的提交记录。
与性能测试不同,压力测试侧重于真实业务,每天进行长时间的压测,保证当天代码的稳定性。
目前每天压测10小时左右,像内存泄漏这种问题就能够测出来。这个压测的页面以后会放到官网上。大家提完PR后,第二天就可以看到效果。
Sharding-Proxy在经历了一年多的磨练后已经走向成熟,开始逐渐被部署到生产环境使用。欢迎感兴趣的小伙伴试用,使用过程中有什么问题可以加微信群讨论。如果大家有什么想法、意见和建议,也欢迎留言与我们交流,更欢迎加入到ShardingSphere的开源项目中。
2020年9月11日,北京,Gdevops全球敏捷运维峰会将开启年度首站!重点围绕数据库、智慧运维、Fintech金融科技领域,携手阿里、腾讯、蚂蚁金服、中国银行、平安银行、中邮消费金融、建设银行、工商银行、农业银行、民生银行、58到家、中国联通大数据、浙江移动、新炬网络等技术代表,展望云时代下数据库发展趋势、破解运维转型困局。
编辑

Gdevops全球敏捷运维峰会北京站:https://www.bagevent.com/event/6243820?bag_track=dbaplus游戏网
编后语:关于《Sharding-Proxy核心原理与性能优化》关于知识就介绍到这里,希望本站内容能让您有所收获,如有疑问可跟帖留言,值班小编第一时间回复。 下一篇内容是有关《魔妆镜十问十答,还原一个真实的智能AR试妆镜》,感兴趣的同学可以点击进去看看。




























































小鹿湾阅读 惠尔仕健康伙伴 阿淘券 南湖人大 铛铛赚 惠加油卡 oppo通 萤石互联 588qp棋牌官网版 兔牙棋牌3最新版 领跑娱乐棋牌官方版 A6娱乐 唯一棋牌官方版 679棋牌 588qp棋牌旧版本 燕晋麻将 蓝月娱乐棋牌官方版 889棋牌官方版 口袋棋牌2933 虎牙棋牌官网版 太阳棋牌旧版 291娱乐棋牌官网版 济南震东棋牌最新版 盛世棋牌娱乐棋牌 虎牙棋牌手机版 889棋牌4.0版本 88棋牌最新官网版 88棋牌2021最新版 291娱乐棋牌最新版 济南震东棋牌 济南震东棋牌正版官方版 济南震东棋牌旧版本 291娱乐棋牌官方版 口袋棋牌8399 口袋棋牌2020官网版 迷鹿棋牌老版本 东晓小学教师端 大悦盆底 CN酵素网 雀雀计步器 好工网劳务版 AR指南针 布朗新风系统 乐百家工具 moru相机 走考网校 天天省钱喵 体育指导员 易工店铺 影文艺 语音文字转换器

