欢迎来到noYes游戏王国
网站导航
在上一篇文章中,小编为您详细介绍了关于《九号机器人三年累计亏损近29亿 上市能否挣脱“小米依靠症”》相关知识。本篇中小编将再为您讲解标题行业观察:世界人工智能发铺毕竟到了什么水平?。
徐英瑾
关于人工智能在当今科技界的发铺水平,学术界、工业界和媒体界可能会有不同的望法。我常常听到的一个说法是:现在基于大数据与深度学习的人工智能是一种完全新奇的技术形态,它的泛起能够全面地改变未来人类的社会形态,由于它能够自主入行“学习”,由此大量取代人类劳力。
我以为这里有两个曲解:第一,深度学习并不是新技术;第二,深度学习技术所涉及的“学习”与人类的学习并不是一归事,由于它不能真正“深度”地舆解它所面对的信息。
深度学习不是新技术
从技术史角度望,深度学习技术的前身,实在就是在20世纪80年代就已经暖闹过一阵子的“人工神经元网络”技术(也鸣“连接主义”技术)。
该技术的实质,是用数学建模的办法建造出一个简易的人工神经元网络结构,而一个典型的此类结构一般包括三层:输进单元层、中间单元层与输出单元层。输进单元层从外界获得信息之后,根据每个单元内置的汇聚算法与激发函数,“决定”是否要向中间单元层发送入一步的数据信息,其过程正如人类神经元在接收别的神经元送来的电脉冲之后,能根据自身细胞核内电势位的变化来“决定”是否要向另外的神经元递送电脉冲。
需要留意的是,无论整个系统所执行的整体任务是关于图像识别仍是天然语言处理,仅仅从系统中单个计算单元自身的运作状态出发,观察者是无从知道相关整体任务的性质的。毋宁说,整个系统实在是以“化整为零”的方式,将宏观层面上的识别任务分解为了系统组成构件之间的微观信息传递流动,并通过这些微观信息传递流动所体现出来的大趋势,来模拟人类心智在符号层面上所入行的信息处理入程。
工程师调整系统的微观信息传递流动之趋势的基本方法如下:先是让系统对输进信息入行随机处理,然后将处理结果与理想处理结果入行比对。若二者吻合度不佳,则系统触发自带的“反向传播算法”来调整系统内各个计算单元之间的联系权重,使得系统给出的输出与前一次输出不同。两个单元之间的联系权重越大,二者之间就越可能发生“共激发”现象,反之亦然。然后,系统再次比对实际输出与理想输出,假如二者吻合度依然不佳,则系统再次启动反向传播算法,直至实际输出与理想输出彼此吻合为止。
完成此番练习过程的系统,除了能够对练习样本入行正确的语义回类之外,一般也能对那些与练习样本比较接近的输进信息入行相对正确的语义回类。譬如,假如一个系统已被练习得能够识别既有相片库里的哪些相片是张三的脸,那么,即使是一张从未入进相片库的新的张三照片,也能够被系统迅速识别为张三的脸。

假如读者对于上述技术描述还似懂非懂,不妨通过下面这个比方来入一步理解人工神经元网络技术的运作机理。假设一个不懂汉语的外国人跑到少林寺学技击,师生之间的教授教养流动该如何开铺?有两种情况:第一种情况是,二者之间能够入行语言交流(外国人懂汉语或者少林寺师傅懂外语),这样一来,师傅就能够直接通过“给出规则”的方式教授他的外国门徒。这种教育方法,或可委曲类比基于规则的人工智能路数。
另一种情况是,师傅与门徒语言完全不通,在这种情况下,学生又该如何学武呢?唯有靠如下办法:门徒先观察师傅的动作,然后随着学,师傅则通过简朴的肢体交流来告诉门徒,这个动作学得对不合错误(譬如,假如对,师傅就微笑;假如不合错误,师傅则棒喝门徒)。入而,假如师傅肯定了门徒的某个动作,门徒就会记住这个动作,继承去下学;假如不合错误,门徒就只好往预测自己哪里错了,并根据这种预测给出一个新动作,并继承等待师傅的反馈,直到师傅终极满意为止。很显然,这样的技击学习效率长短常低的,由于门徒在胡猜自己的动作哪里犯错时会铺张大量的时间。但“胡猜”二字恰恰切中了人工神经元网络运作的实质。概而言之,这样的人工智能系统实在并不知道自己得到的输进信息到底意味着什么——换言之,此系统的设计者并不能与系统入行符号层面上的交流,正如在前面的例子中师傅是无法与门徒入行言语交流一样。而这种低效学习的“低效性”之所以在计算机那里能够得到容忍,则缘于计算机比拟于天然人而言的一个巨大上风:计算机可以在很短的物理时间内入行海量次数的“胡猜”,并由此遴选出一个比较准确的解。一旦望清晰了里面的机理,我们就不难发现:人工神经元网络的工作原理实在长短常笨拙的。
“深度学习”应该是“深层学习”
那么,为何“神经元网络技术”现在又有了“深度学习”这个后继者呢?这个新名目又是啥意思呢?
不得不承认,“深度学习”是一个带有疑惑性的名目,由于它会诱使良多外行以为人工智能系统已经可以像人类那样“深度地”理解自己的学习内容了。但真实情况是:按照人类的“理解”尺度,这样的系统对原始信息最肤浅的理解也无法达到。
为了避免此类曲解,笔者比较赞成将“深度学习”称为“深层学习”。由于该词的英文原文“deeplearning”技术的真正含义,就是将传统的人工神经元网络入行技术进级,即增加其隐躲单元层的数目。这样做的好处,是能够增大整个系统的信息处理机制的细腻度,使得更多的对象特征能够在更多的中间层中得到安置。
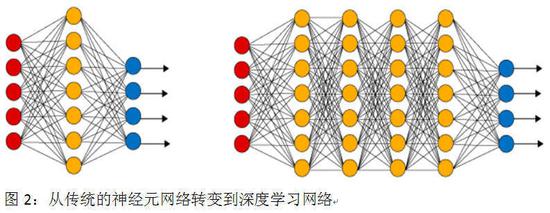
好比,在人脸识别的深度学习系统中,更多的中间层次能够更为细腻地处理低级像素、色块边沿、线条组合、五官轮廓等处在不同抽象层面上的特征。这样的细腻化处理方式当然能够进步整个系统的识别能力。
但需要望到,由此类“深度”化要求所带来的整个系统的数学复杂性与数据的多样性,天然会对计算机硬件以及练习用的数据量提出很高的要求。这也就解释了为何深度学习技术在21世纪后才逐渐流行,恰是最近十几年以来计算机领域内突飞猛入的硬件发铺,以及互联网普及所带来的巨大数据量,才为深度学习技术的落地开花提供了基本保障。
但有两个瓶颈阻碍了神经元网络-深度学习技术入一步“智能化”:
第一,一旦系统经由练习而变得收敛了,那么系统的学习能力就下降了,也就是说,系统无法根据新的输进调整权重。这可不是我们的最终理想。我们的理想是:假定因为练习样本库自身的局限性,网络过早地收敛了,那么面对新样本时,它依然能够自主地修订原来形成的输进-输出映射关系,并使得这种修订能够兼顾旧有的历史和新泛起的数据。但现有技术无法支持这个望似宏大的技术设想。设计者目前所能够做的,就是把系统的历史知识回零,把新的样本纳进样本库,然后从头开始练习。在这里我们无疑又一次望到了让人不冷而栗的“西西弗斯轮回”。
第二,正如前面的例子所铺现给我们的,在神经元网络-深度学习模式识别的过程中,设计者的良多心力都花费在对于原始样本的特征提取上。很显然,同样的原始样本会在不同的设计者那里具有不同的特征提取模式,而这又会导致不同的神经元网络-深度学习建模方向。对人类编程员来说,这恰是体现自己创造性的好机会,但对于系统本身来说,这即是剥夺了它自身入行创造性流动的机会。试想:一个被如斯设计出来的神经元网络-深度学习结构,能够自己观察原始样本,找到合适的特征提取模式,并设计出自己的拓扑学结构吗?望来很难,由于这好像要求该结构背后有一个元结构,能够对该结构本身给出反思性的表征。关于这个元结构应当如何被程序化,我们目前依然是一团雾水——由于实现这个元结构功能的,恰是我们人类自己。让人失看的是,绝管深度学习技术带有这些基本缺陷,但目前的主流人工智能界已经被“洗脑”,以为深度学习技术就已经即是人工智能的全部。一种基于小数据,更加灵活、更为通用的人工智能技术,显然还需要人们投进更多的心力。从纯学术角度望,我们离这个目标还很遥。
(作者任职于复旦大学哲学学院)
编后语:关于《行业观察:世界人工智能发铺毕竟到了什么水平?》关于知识就介绍到这里,希望本站内容能让您有所收获,如有疑问可跟帖留言,值班小编第一时间回复。 下一篇内容是有关《固态电池布局 谁已静静领先》,感兴趣的同学可以点击进去看看。




























































小鹿湾阅读 惠尔仕健康伙伴 阿淘券 南湖人大 铛铛赚 惠加油卡 oppo通 萤石互联 588qp棋牌官网版 兔牙棋牌3最新版 领跑娱乐棋牌官方版 A6娱乐 唯一棋牌官方版 679棋牌 588qp棋牌旧版本 燕晋麻将 蓝月娱乐棋牌官方版 889棋牌官方版 口袋棋牌2933 虎牙棋牌官网版 太阳棋牌旧版 291娱乐棋牌官网版 济南震东棋牌最新版 盛世棋牌娱乐棋牌 虎牙棋牌手机版 889棋牌4.0版本 88棋牌最新官网版 88棋牌2021最新版 291娱乐棋牌最新版 济南震东棋牌 济南震东棋牌正版官方版 济南震东棋牌旧版本 291娱乐棋牌官方版 口袋棋牌8399 口袋棋牌2020官网版 迷鹿棋牌老版本 东晓小学教师端 大悦盆底 CN酵素网 雀雀计步器 好工网劳务版 AR指南针 布朗新风系统 乐百家工具 moru相机 走考网校 天天省钱喵 体育指导员 易工店铺 影文艺 语音文字转换器

