欢迎来到noYes游戏王国
网站导航
在上一篇文章中,小编为您详细介绍了关于《美研究者用3D打印的小鼠肌肉构造生物机器人,有望用于假肢制造》相关知识。本篇中小编将再为您讲解标题OpenAI打造AI“百变歌姬”!训练120万首歌曲,化身猫王布兰妮。
原标题:OpenAI打造AI“百变歌姬”!训练120万首歌曲,化身猫王布兰妮

智东西(公众号:zhidxcom)编 | 董温淑
智东西5月6日消息,近日,非营利人工智能研究组织OpenAI利用神经网络研发出一款“自动点唱机”——Jukebox。无论是摇滚、Hip-Hop还是爵士,Jukebox都能毫无压力地生成相应风格的音乐。
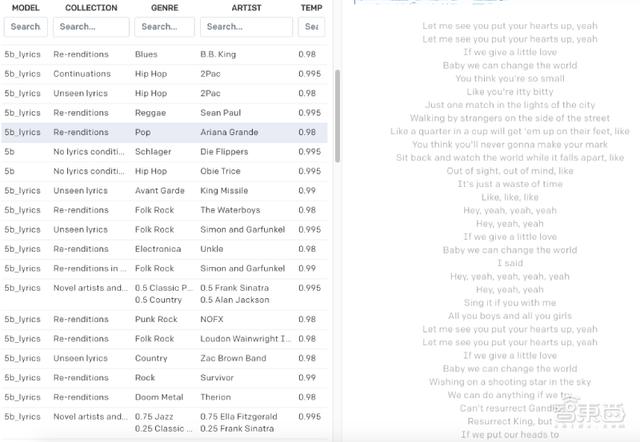
相较之前的音乐生成工具,Jukebox能精准捕捉到人类的声音以及更微妙的音色、力度和表现力等特征,只要输入流派、艺术家和歌词,就能生成相应风格的高仿真音乐或歌声。
这项研究发表在OpenAI官网上,论文标题为《Jukebox:一个音乐生成模型(Jukebox: A Generative Model for Music)》
GitHub代码:https://github.com/openai/jukebox/
论文链接:https://cdn.openai.com/papers/jukebox.pdf

一、音频序列较长,建模十分困难
对自动生成音乐的探索可以追溯到半个多世纪之前。
一种典型方法是钢琴卷帘(Piano Roll),即通过指定要每个音符的演奏乐器、音高、时间和速度,象征性地用自动钢琴琴键弹奏的方式来产生音乐。
曾有研究者用这种音乐生成方法生成1分钟长的巴赫合唱、多乐器演奏复调音乐、以及数分钟长的音乐作品。
不过,这种按单个音符生成音乐的方法有局限性,无法捕捉人类的声音及更微妙的音色、力度和表现力等特征,而这些特征对于演奏的效果十分重要。
还有一种方法是直接将音乐建模成原始音频。相比于对音符建模,在音频级别上生成音乐更加困难。
这是因为音频级别的音乐拥有更长的序列。比如,一首典型的4分钟长的CD品质(44kHz,16-bit)音乐,就有超过1000万个时间步长(timestep)。
1000万是什么概念?要知道,OpenAI参数量高达15亿的通用语言模型GPT-2只有1000个时间步长,完虐Dota 2人类选手的OpenAI Five每场比赛也仅耗费数万个时间步长。
因此,要学习音乐的高级语义,模型需引入长时记忆(long-range dependency)关系,以生成时间更长、结构更多样、音色更多元的音频。
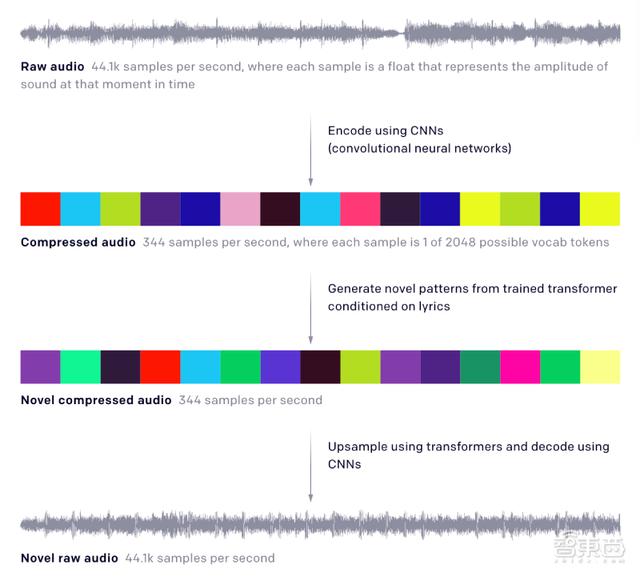
解决长输入问题的一种方法是使用自动编码器,通过舍弃一些在感知上不相关的信息位,将原始音频压缩到较低维度的空间,然后训练模型在此压缩空间中生成音频,并通过上采样最终回到原始音频空间,最终生成与预期风格相近的音乐。
二、用120万首歌曲训练!跟布兰妮和席琳·迪翁学流行音乐
研究人员选用分层VQ-VAE模型(hierarchical VQ-VAE architecture)来压缩原始音频,再用一个自回归稀疏Transformer来预测音乐,同时训练一个自回归上采样算法来重现每个层次中丢失的信息。
1、压缩原始音频
之前的研究证明,分层VQ-VAE模型可以生成高保真图像。OpenAI研究人员认为,可以借助这一模型来把原始音频压缩为离散的代码。
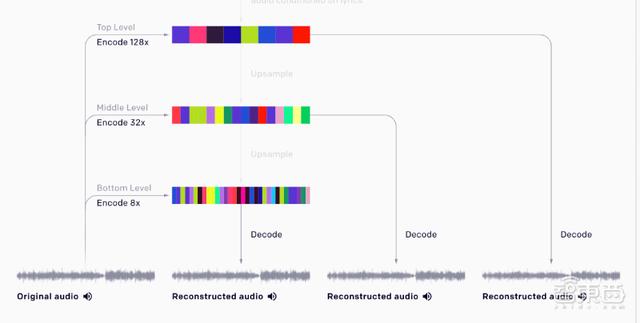
研究人员从3个不同的抽象层次为原始音频建模,每个VQ-VAE层次独立编码输入,底层编码产生最高质量的重构,顶层编码只保留基本的音乐信息。在每一层,利用WaveNet式非因果关系1-D扩张卷积组成的残差网络,交织下采样和上采样1-D卷积,以此匹配不同的跳跃长度。
三个层次分别将44kHz的原始音频按照8x、32x、128x压缩,每个层次的码本大小(codebook size)为2048。
通过这种降采样方法生成的音频损失了大部分的细节,当进一步降低音量时会出现明显的噪声。但是,它保留了关于音调、音色和音量的基本信息。
2、生成音乐代码
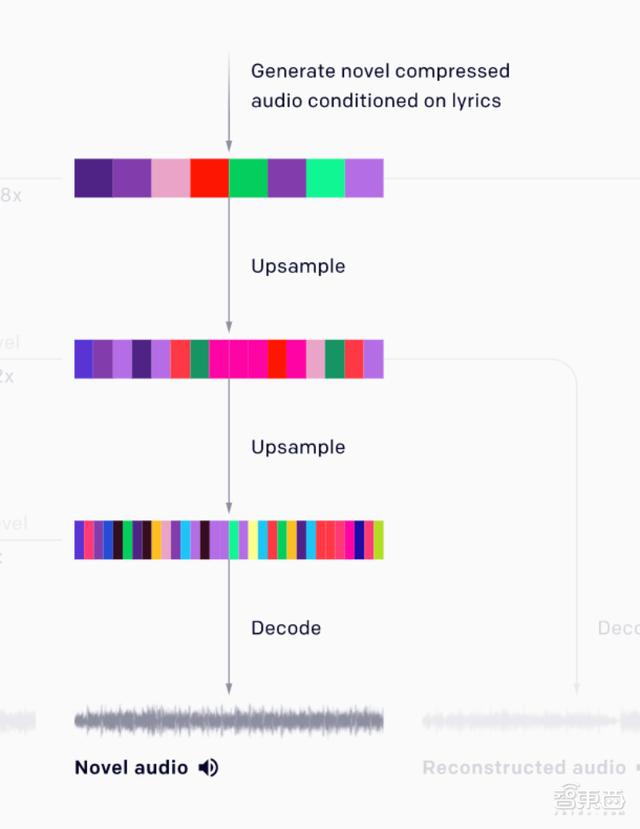
接下来,研究人员用一个简化的自回归稀疏Transformer训练模型,使模型学习VQ-VAE模型编码的音乐代码的分布,并使模型在这个离散的空间中产生音乐。
同样地,研究人员也从3个层次建模:1个顶层的先验模型,可以生成最多的压缩代码;两个上采样先验模型,生成较少的压缩代码。
顶层先验模型模拟音乐的长期结构(long-range structure),从这一层次解码的样本音频质量较低,但是能捕捉到歌唱、旋律等高级语义。
中层和底层的上采样先验模型可以模拟出音色等特征,显著提升音质。
一旦所有的先验模型都经过训练,研究人员就可以从顶层先验模型生成代码,并用上采样先验模型对代码进行上采样,再用VQ-VAE解码器将代码解码为原始音频。
3、用120万首歌曲进行训练
模型搭建好后,研究人员从网络上搜集了120万首歌曲(其中半数为英文歌曲)对其进行训练,还引入了歌词百科LyricWiki中的歌词和元数据提升训练效果。
元数据包括艺术家、专辑风格、歌曲年份、每首歌表达的常见情绪和播放列表关键字等。研究人员用32-bit,44.1kHz的原始音频进行训练。除了原始音频,研究人员还通过随机向下混合左右声道产生单声道音频来加强训练效果。
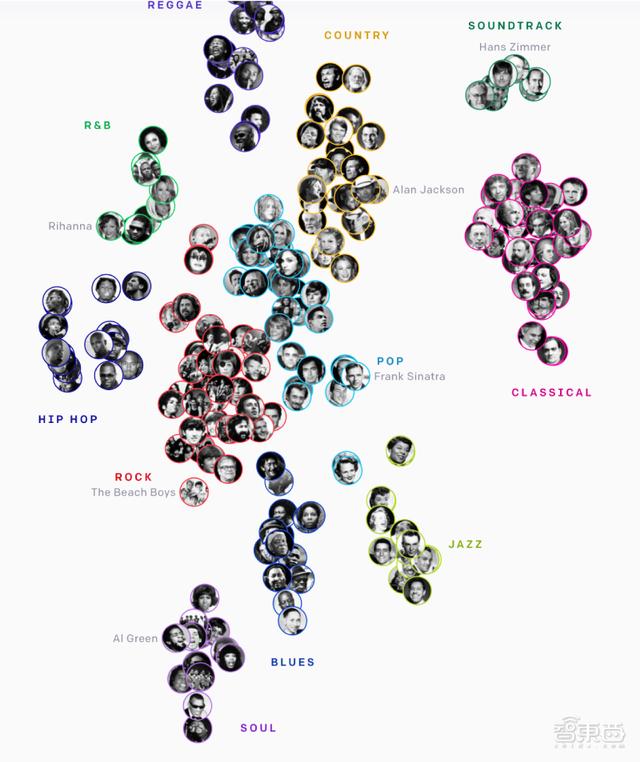
为了使生成的音乐效果更好,研究人员指定了生成歌曲的歌手和艺术风格。训练结果显示,模型可以在无监督方式下将风格相似的艺术家或流派分为一类。
模型将120万首歌曲及音乐家等数据分类为雷鬼音乐、乡村音乐、电影原声带、古典音乐、POP、爵士乐、布鲁斯音乐、灵魂乐、摇滚乐、Hip-Hop和R&B等。
为了使歌词与音频相匹配,研究人员设计了一个简单的方案:训练时,为每个字符设置一个固定播放时长的窗口,随着音乐持续,歌词字符按时间顺序播放。
训练结果显示,借助这一方案,大部分歌词都能与音频相匹配,除了语速较快的Hip-Hop音乐。
为了解决这一问题,研究人员使用音轨分离软件Spleeter从每首歌曲中提取人声,再用自动歌词排列工具NUS AutoLyricsAlign为提取出的人声实现单词级别的匹配,以此达到精确的歌词匹配效果。
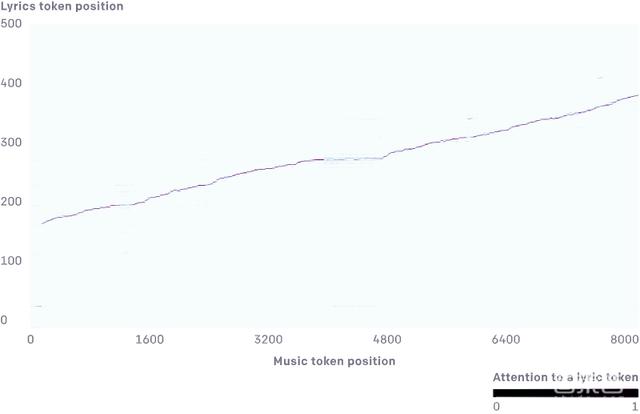
▲模型对抒情歌词的匹配情况
三、局限性:无法生成合唱音乐
尽管Jukebox能够生成各种流派和艺术风格的音乐,提升了自动生成音频的音质、连贯性和长度,但它还有一些局限性。
首先,Jukebox生成的音乐与人类创造的音乐间还存在较大差距。比如,虽然Jukebox能够生成效果很好的独唱音乐,但它目前还无法生成合唱等结构更加复杂的音乐。
研究人员称,改进分层VQ-VAE模型、使其能够捕捉更多的音乐信息可以改善这个缺陷。
其次,Jukebox的采样速度也很慢,渲染1分钟的音乐需要花费约9个小时,因此Jukebox还不能用于交互式应用程序。
论文指出,将模型提取到并行采样器(parallel sampler)中可以提升采样速度。
另外,目前模型主要采用用英文歌词、西方音乐进行训练,还未生成更多语种的歌曲。
研究人员认为,尽管目前Jukebox模型还无法直接用于音乐创作,但在未来,Jukebox或可在音乐家的创作过程中提供辅助。
论文中还指出,目前OpenAI团队已经与10位音乐家进行了沟通,希望后者为研究人员提供反馈。
结语:或可用于简化音乐创作流程
相比于之前的音乐生成模型,OpenAI团队研发的Jukebox模型有很大进步,可以自动生成高度仿真的人类歌声音频,而且生成的内容涵盖各种音乐流派。
在未来,Jukebox或可用于简化音乐创作流程,帮助更多人实现音乐梦想。论文中写道:“许多怀抱音乐梦想的人并没有机会接受专业训练,因此我们认为它(Jukebox)将会成为人类音乐家的重要工具。”
文章来源:OpenAI游戏网
编后语:关于《OpenAI打造AI“百变歌姬”!训练120万首歌曲,化身猫王布兰妮》关于知识就介绍到这里,希望本站内容能让您有所收获,如有疑问可跟帖留言,值班小编第一时间回复。 下一篇内容是有关《报告:一季度全球智能手表出货量达1370万部同比增长20%》,感兴趣的同学可以点击进去看看。




























































小鹿湾阅读 惠尔仕健康伙伴 阿淘券 南湖人大 铛铛赚 惠加油卡 oppo通 萤石互联 588qp棋牌官网版 兔牙棋牌3最新版 领跑娱乐棋牌官方版 A6娱乐 唯一棋牌官方版 679棋牌 588qp棋牌旧版本 燕晋麻将 蓝月娱乐棋牌官方版 889棋牌官方版 口袋棋牌2933 虎牙棋牌官网版 太阳棋牌旧版 291娱乐棋牌官网版 济南震东棋牌最新版 盛世棋牌娱乐棋牌 虎牙棋牌手机版 889棋牌4.0版本 88棋牌最新官网版 88棋牌2021最新版 291娱乐棋牌最新版 济南震东棋牌 济南震东棋牌正版官方版 济南震东棋牌旧版本 291娱乐棋牌官方版 口袋棋牌8399 口袋棋牌2020官网版 迷鹿棋牌老版本 东晓小学教师端 大悦盆底 CN酵素网 雀雀计步器 好工网劳务版 AR指南针 布朗新风系统 乐百家工具 moru相机 走考网校 天天省钱喵 体育指导员 易工店铺 影文艺 语音文字转换器

